13: Hash Tables & Hash Functions
Hash Tables & Hash Functions Advanced
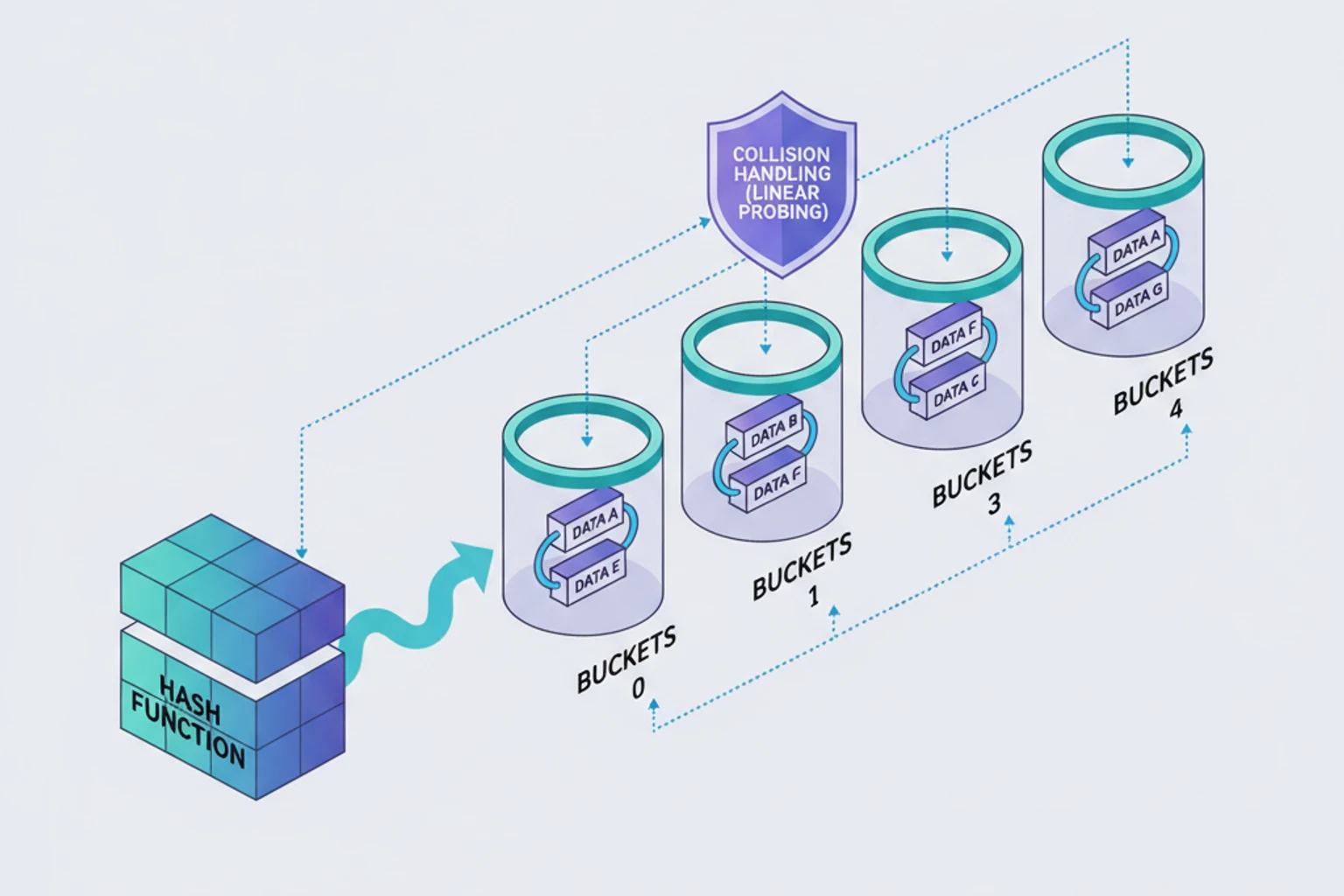
Section titled “Hash Tables & Hash Functions Advanced”Hash tables are one of the most important data structures in computer science, providing O(1) average-case lookups, insertions, and deletions. Think of them as the secret sauce behind PHP’s lightning-fast associative arrays! In this chapter, we’ll build hash tables from scratch, design hash functions, and handle collisions like a pro.
Why hash tables matter: They power databases, caches, compilers, and even PHP’s native arrays. Understanding them deeply will make you a better developer and help you solve complex problems efficiently.
What You’ll Learn
Section titled “What You’ll Learn”Estimated time: 60 minutes
By the end of this chapter, you will:
- Build hash tables from scratch with proper hash functions achieving O(1) lookups
- Implement collision handling using separate chaining and open addressing (linear probing, quadratic probing, double hashing)
- Master advanced techniques like Robin Hood, Cuckoo, and Hopscotch hashing
- Design effective hash functions with uniform distribution and minimal collisions
- Apply hash tables to solve real-world problems: caching, frequency counting, duplicate detection
- Understand security considerations and protect against hash flooding DoS attacks
- Leverage PHP’s built-in arrays (which ARE hash tables) effectively
Prerequisites
Section titled “Prerequisites”Before starting this chapter, ensure you have:
- ✓ Understanding of arrays and how they work (fundamental concept)
- ✓ Familiarity with linked lists (helpful but not required - we’ll explain as needed)
- ✓ Completion of Chapters 11-12 search algorithms (95 mins if not done)
- ✓ Basic understanding of O(1) time complexity (Chapter 1 for review)
Quick Checklist
Section titled “Quick Checklist”Complete these hands-on tasks as you work through the chapter:
- Build a simple hash table with a basic hash function
- Implement collision handling with separate chaining
- Create open addressing with linear probing
- Test different hash functions (division, multiplication, polynomial)
- Implement dynamic resizing based on load factor
- Build Robin Hood hashing for improved performance
- Create a practical caching system using hash tables
- Solve the Two Sum problem with O(n) complexity
- Implement secure hash table resistant to DoS attacks
- Benchmark hash table performance vs linear search
What Is a Hash Table?
Section titled “What Is a Hash Table?”A hash table (or hash map) stores key-value pairs and uses a hash function to compute an index where the value should be stored.
Concept:
Key → Hash Function → Index → Value
"Alice" → hash("Alice") → 3 → "alice@example.com""Bob" → hash("Bob") → 7 → "bob@example.com"Array representation:
Index: 0 1 2 3 4 5 6 7Value: null null null alice@...com null null null bob@...comHow Hash Tables Work
Section titled “How Hash Tables Work”The Hash Function
Section titled “The Hash Function”A hash function converts a key into an array index:
function simpleHash(string $key, int $size): int{ $hash = 0;
for ($i = 0; $i < strlen($key); $i++) { $hash += ord($key[$i]); }
return $hash % $size; // Mod to fit in array}
echo simpleHash("Alice", 10); // Some index 0-9echo simpleHash("Bob", 10); // Some index 0-9Basic Hash Table Operations
Section titled “Basic Hash Table Operations”- Insert: hash(key) → index, store value at index
- Search: hash(key) → index, retrieve value at index
- Delete: hash(key) → index, remove value at index
All O(1) average case!
Building a Simple Hash Table
Section titled “Building a Simple Hash Table”Let’s start with the simplest possible hash table implementation:
class HashTable{ private array $table; private int $size;
public function __construct(int $size = 100) { $this->size = $size; $this->table = array_fill(0, $size, null); }
private function hash(string $key): int { $hash = 0;
for ($i = 0; $i < strlen($key); $i++) { $hash = ($hash * 31 + ord($key[$i])) % $this->size; }
return $hash; }
public function set(string $key, mixed $value): void { $index = $this->hash($key); $this->table[$index] = $value; }
public function get(string $key): mixed { $index = $this->hash($key); return $this->table[$index]; }
public function delete(string $key): void { $index = $this->hash($key); $this->table[$index] = null; }
public function has(string $key): bool { $index = $this->hash($key); return $this->table[$index] !== null; }}
// Usage$ht = new HashTable();$ht->set("name", "Alice");$ht->set("age", 30);
echo $ht->get("name"); // Aliceecho $ht->get("age"); // 30Problem: What happens when two keys hash to the same index? Collision!
Collision Handling
Section titled “Collision Handling”Two main strategies for handling collisions:
1. Separate Chaining
Section titled “1. Separate Chaining”Store multiple key-value pairs at each index using a linked list or array. This is the most common approach and what PHP’s arrays use internally:
class HashTableChaining{ private array $table; private int $size; private int $count = 0;
public function __construct(int $size = 100) { $this->size = $size; $this->table = array_fill(0, $size, []); }
private function hash(string $key): int { $hash = 0;
for ($i = 0; $i < strlen($key); $i++) { $hash = ($hash * 31 + ord($key[$i])) % $this->size; }
return abs($hash); }
public function set(string $key, mixed $value): void { $index = $this->hash($key);
// Check if key already exists foreach ($this->table[$index] as &$pair) { if ($pair['key'] === $key) { $pair['value'] = $value; return; } }
// Add new key-value pair $this->table[$index][] = ['key' => $key, 'value' => $value]; $this->count++; }
public function get(string $key): mixed { $index = $this->hash($key);
foreach ($this->table[$index] as $pair) { if ($pair['key'] === $key) { return $pair['value']; } }
return null; }
public function delete(string $key): bool { $index = $this->hash($key);
foreach ($this->table[$index] as $i => $pair) { if ($pair['key'] === $key) { array_splice($this->table[$index], $i, 1); $this->count--; return true; } }
return false; }
public function has(string $key): bool { return $this->get($key) !== null; }
public function size(): int { return $this->count; }
public function keys(): array { $keys = [];
foreach ($this->table as $bucket) { foreach ($bucket as $pair) { $keys[] = $pair['key']; } }
return $keys; }
public function values(): array { $values = [];
foreach ($this->table as $bucket) { foreach ($bucket as $pair) { $values[] = $pair['value']; } }
return $values; }
public function getLoadFactor(): float { return $this->count / $this->size; }}
// Usage$ht = new HashTableChaining();$ht->set("Alice", "alice@example.com");$ht->set("Bob", "bob@example.com");$ht->set("Charlie", "charlie@example.com");
echo $ht->get("Bob"); // bob@example.comprint_r($ht->keys()); // ['Alice', 'Bob', 'Charlie']2. Open Addressing
Section titled “2. Open Addressing”Store all entries in the main array, probe for the next available slot on collision. This uses less memory than chaining but can suffer from clustering.
Linear Probing
Section titled “Linear Probing”class HashTableLinearProbing{ private array $keys; private array $values; private int $size; private int $count = 0;
public function __construct(int $size = 100) { $this->size = $size; $this->keys = array_fill(0, $size, null); $this->values = array_fill(0, $size, null); }
private function hash(string $key): int { $hash = 0;
for ($i = 0; $i < strlen($key); $i++) { $hash = ($hash * 31 + ord($key[$i])) % $this->size; }
return abs($hash); }
public function set(string $key, mixed $value): void { if ($this->count >= $this->size * 0.7) { $this->resize(); }
$index = $this->hash($key);
// Linear probing: find next available slot while ($this->keys[$index] !== null && $this->keys[$index] !== $key) { $index = ($index + 1) % $this->size; }
$isNew = $this->keys[$index] === null; $this->keys[$index] = $key; $this->values[$index] = $value;
if ($isNew) { $this->count++; } }
public function get(string $key): mixed { $index = $this->hash($key);
// Linear probing: search for key while ($this->keys[$index] !== null) { if ($this->keys[$index] === $key) { return $this->values[$index]; } $index = ($index + 1) % $this->size; }
return null; }
public function delete(string $key): bool { $index = $this->hash($key);
// Find the key while ($this->keys[$index] !== null) { if ($this->keys[$index] === $key) { $this->keys[$index] = null; $this->values[$index] = null; $this->count--;
// Rehash subsequent entries $this->rehashFrom($index); return true; } $index = ($index + 1) % $this->size; }
return false; }
private function rehashFrom(int $start): void { $index = ($start + 1) % $this->size;
while ($this->keys[$index] !== null) { $key = $this->keys[$index]; $value = $this->values[$index];
$this->keys[$index] = null; $this->values[$index] = null; $this->count--;
$this->set($key, $value);
$index = ($index + 1) % $this->size; } }
private function resize(): void { $oldKeys = $this->keys; $oldValues = $this->values;
$this->size *= 2; $this->keys = array_fill(0, $this->size, null); $this->values = array_fill(0, $this->size, null); $this->count = 0;
foreach ($oldKeys as $i => $key) { if ($key !== null) { $this->set($key, $oldValues[$i]); } } }}Quadratic Probing
Section titled “Quadratic Probing”Reduces clustering by using quadratic increments instead of linear:
private function quadraticProbe(string $key): int{ $index = $this->hash($key); $i = 0;
// Try index, index + 1², index + 2², etc. while ($this->keys[$index] !== null && $this->keys[$index] !== $key) { $i++; $index = ($this->hash($key) + $i * $i) % $this->size; }
return $index;}Double Hashing
Section titled “Double Hashing”Uses a second hash function to determine the probe sequence, providing better distribution:
private function doubleHash(string $key): int{ $hash1 = $this->hash($key); $hash2 = 7 - ($hash1 % 7); // Secondary hash function
$index = $hash1; $i = 0;
while ($this->keys[$index] !== null && $this->keys[$index] !== $key) { $i++; $index = ($hash1 + $i * $hash2) % $this->size; }
return $index;}Designing Good Hash Functions
Section titled “Designing Good Hash Functions”Properties of Good Hash Functions
Section titled “Properties of Good Hash Functions”- Deterministic: Same input always produces same output
- Uniform distribution: Spreads keys evenly across table
- Fast to compute: O(1) complexity
- Minimizes collisions
Common Hash Function Techniques
Section titled “Common Hash Function Techniques”1. Division Method
Section titled “1. Division Method”Simple but effective - use modulo operation:
function hashDivision(string $key, int $size): int{ $hash = 0;
for ($i = 0; $i < strlen($key); $i++) { $hash += ord($key[$i]); }
return $hash % $size;}2. Multiplication Method
Section titled “2. Multiplication Method”Uses the golden ratio for better distribution:
function hashMultiplication(string $key, int $size): int{ $hash = 0; $A = 0.6180339887; // Golden ratio
for ($i = 0; $i < strlen($key); $i++) { $hash += ord($key[$i]); }
return (int)($size * (($hash * $A) - floor($hash * $A)));}3. Polynomial Rolling Hash
Section titled “3. Polynomial Rolling Hash”Best for strings - reduces collisions significantly:
function hashPolynomial(string $key, int $size): int{ $hash = 0; $prime = 31; // Prime number
for ($i = 0; $i < strlen($key); $i++) { $hash = ($hash * $prime + ord($key[$i])) % $size; }
return abs($hash);}4. FNV-1a Hash (Fast, Good Distribution)
Section titled “4. FNV-1a Hash (Fast, Good Distribution)”Industry-standard non-cryptographic hash:
function hashFNV1a(string $key): int{ $hash = 2166136261; // FNV offset basis
for ($i = 0; $i < strlen($key); $i++) { $hash ^= ord($key[$i]); $hash *= 16777619; // FNV prime }
return abs($hash);}PHP’s Built-in Hash Functions
Section titled “PHP’s Built-in Hash Functions”// For strings - very fast$hash = crc32("my-key");
// Cryptographic (slower, but better distribution)$hash = hash('fnv1a32', "my-key");
// MD5 (don't use for security, but okay for hash tables)$hash = md5("my-key", true);Load Factor and Resizing
Section titled “Load Factor and Resizing”Load factor = number of entries / table size
A high load factor means more collisions and slower operations. Resize when it gets too high:
class ResizableHashTable extends HashTableChaining{ private const MAX_LOAD_FACTOR = 0.75;
public function set(string $key, mixed $value): void { parent::set($key, $value);
// Resize if load factor too high if ($this->getLoadFactor() > self::MAX_LOAD_FACTOR) { $this->resize(); } }
private function resize(): void { $oldTable = $this->table; $this->size *= 2; $this->table = array_fill(0, $this->size, []); $this->count = 0;
// Rehash all entries foreach ($oldTable as $bucket) { foreach ($bucket as $pair) { $this->set($pair['key'], $pair['value']); } } }}When to resize:
- Load factor > 0.75: table getting full, more collisions
- Load factor < 0.25: table too empty, wasting space
Real-World Applications
Section titled “Real-World Applications”1. Caching
Section titled “1. Caching”Build a simple LRU-style cache using hash tables:
class Cache{ private HashTableChaining $cache; private int $maxSize;
public function __construct(int $maxSize = 100) { $this->cache = new HashTableChaining($maxSize); $this->maxSize = $maxSize; }
public function get(string $key): mixed { return $this->cache->get($key); }
public function set(string $key, mixed $value): void { if ($this->cache->size() >= $this->maxSize) { // Evict oldest entry (simplified) $keys = $this->cache->keys(); $this->cache->delete($keys[0]); }
$this->cache->set($key, $value); }}2. Counting Frequencies
Section titled “2. Counting Frequencies”Count word occurrences - O(n) instead of O(n²):
function countFrequencies(array $items): array{ $frequencies = new HashTableChaining();
foreach ($items as $item) { $count = $frequencies->get($item) ?? 0; $frequencies->set($item, $count + 1); }
// Convert to array $result = []; foreach ($frequencies->keys() as $key) { $result[$key] = $frequencies->get($key); }
return $result;}
$words = ['apple', 'banana', 'apple', 'cherry', 'banana', 'apple'];print_r(countFrequencies($words));// ['apple' => 3, 'banana' => 2, 'cherry' => 1]3. Detecting Duplicates
Section titled “3. Detecting Duplicates”Check for duplicates in O(n) time:
function hasDuplicates(array $arr): bool{ $seen = new HashTableChaining();
foreach ($arr as $item) { if ($seen->has($item)) { return true; } $seen->set($item, true); }
return false;}
// O(n) instead of O(n²)!4. Two Sum Problem
Section titled “4. Two Sum Problem”Classic interview question - find two numbers that sum to target:
function twoSum(array $nums, int $target): ?array{ $map = new HashTableChaining();
foreach ($nums as $i => $num) { $complement = $target - $num;
if ($map->has((string)$complement)) { return [$map->get((string)$complement), $i]; }
$map->set((string)$num, $i); }
return null;}
$nums = [2, 7, 11, 15];print_r(twoSum($nums, 9)); // [0, 1]PHP’s Built-in Arrays ARE Hash Tables!
Section titled “PHP’s Built-in Arrays ARE Hash Tables!”Mind-blowing fact: PHP arrays are actually hash tables under the hood! This is why PHP arrays are so flexible and fast.
// Associative array = hash table$ages = [ 'Alice' => 30, 'Bob' => 25, 'Charlie' => 35];
// O(1) lookup!echo $ages['Bob']; // 25
// O(1) insert!$ages['David'] = 28;
// O(1) check!if (isset($ages['Alice'])) { echo "Alice exists";}PHP array operations and their complexity:
$arr[$key]→ O(1) get value by key$arr[$key] = $value→ O(1) set/insertisset($arr[$key])→ O(1) check existenceunset($arr[$key])→ O(1) deletearray_key_exists()→ O(1) key existence checkin_array()→ O(n) ⚠️ searches values, not keys! Use hash lookup instead.
Hash Tables vs Other Searches
Section titled “Hash Tables vs Other Searches”Let’s compare hash tables with search methods from previous chapters:
$data = range(1, 100000); // 100k elements
// Linear Search - O(n)$start = microtime(true);$found = in_array(99999, $data); // Worst case: checks all elements$linearTime = microtime(true) - $start;echo "Linear Search: " . ($linearTime * 1000) . "ms\n";
// Binary Search - O(log n) - requires sorted arraysort($data);$start = microtime(true);$found = binarySearch($data, 99999);$binaryTime = microtime(true) - $start;echo "Binary Search: " . ($binaryTime * 1000) . "ms\n";
// Hash Table - O(1)$hashTable = array_flip($data); // Create hash table$start = microtime(true);$found = isset($hashTable[99999]); // Instant lookup!$hashTime = microtime(true) - $start;echo "Hash Table: " . ($hashTime * 1000) . "ms\n";
// Results (approximate):// Linear Search: 2-5ms// Binary Search: 0.01-0.02ms// Hash Table: 0.001-0.002ms ← 100-1000x faster!When each approach wins:
| Data Structure | Best For | Worst For |
|---|---|---|
| Hash Table | Fast lookups, counting, caching | Sorted data, range queries |
| Binary Search | Sorted data, range queries | Frequent insertions |
| Linear Search | Small arrays (<10 items), unsorted | Large datasets |
Advanced Collision Handling Strategies
Section titled “Advanced Collision Handling Strategies”Robin Hood Hashing
Section titled “Robin Hood Hashing”Robin Hood hashing improves on linear probing by reducing variance in probe sequence lengths. It “steals from the rich” by swapping entries to reduce maximum probe distance:
class RobinHoodHashTable{ private array $keys; private array $values; private array $distances; // Distance from ideal position private int $size; private int $count = 0;
public function __construct(int $size = 100) { $this->size = $size; $this->keys = array_fill(0, $size, null); $this->values = array_fill(0, $size, null); $this->distances = array_fill(0, $size, -1); }
private function hash(string $key): int { return abs(crc32($key) % $this->size); }
public function set(string $key, mixed $value): void { $index = $this->hash($key); $distance = 0;
while (true) { // Empty slot found if ($this->keys[$index] === null) { $this->keys[$index] = $key; $this->values[$index] = $value; $this->distances[$index] = $distance; $this->count++; return; }
// Key already exists if ($this->keys[$index] === $key) { $this->values[$index] = $value; return; }
// Robin Hood: if current item is richer (lower distance), swap if ($distance > $this->distances[$index]) { // Swap $tempKey = $this->keys[$index]; $tempValue = $this->values[$index]; $tempDist = $this->distances[$index];
$this->keys[$index] = $key; $this->values[$index] = $value; $this->distances[$index] = $distance;
$key = $tempKey; $value = $tempValue; $distance = $tempDist; }
$index = ($index + 1) % $this->size; $distance++; } }
public function get(string $key): mixed { $index = $this->hash($key); $distance = 0;
while ($this->keys[$index] !== null) { if ($this->keys[$index] === $key) { return $this->values[$index]; }
// If we've gone further than this key's distance, it's not here if ($distance > $this->distances[$index]) { return null; }
$index = ($index + 1) % $this->size; $distance++; }
return null; }}Cuckoo Hashing
Section titled “Cuckoo Hashing”Uses two hash functions and two tables, guaranteeing O(1) worst-case lookup (not just average). Named after the cuckoo bird that kicks other eggs out of nests:
class CuckooHashTable{ private array $table1; private array $table2; private int $size; private int $count = 0; private const MAX_KICKS = 100;
public function __construct(int $size = 100) { $this->size = $size; $this->table1 = array_fill(0, $size, null); $this->table2 = array_fill(0, $size, null); }
private function hash1(string $key): int { return abs(crc32($key) % $this->size); }
private function hash2(string $key): int { $hash = 0; for ($i = 0; $i < strlen($key); $i++) { $hash = ($hash * 31 + ord($key[$i])) % $this->size; } return abs($hash); }
public function set(string $key, mixed $value): void { // Check if key already exists $idx1 = $this->hash1($key); $idx2 = $this->hash2($key);
if ($this->table1[$idx1] !== null && $this->table1[$idx1]['key'] === $key) { $this->table1[$idx1]['value'] = $value; return; }
if ($this->table2[$idx2] !== null && $this->table2[$idx2]['key'] === $key) { $this->table2[$idx2]['value'] = $value; return; }
// Insert new key $item = ['key' => $key, 'value' => $value]; $currentTable = 1; $kicks = 0;
while ($kicks < self::MAX_KICKS) { if ($currentTable === 1) { $idx = $this->hash1($item['key']);
if ($this->table1[$idx] === null) { $this->table1[$idx] = $item; $this->count++; return; }
// Kick out existing item $temp = $this->table1[$idx]; $this->table1[$idx] = $item; $item = $temp; $currentTable = 2; } else { $idx = $this->hash2($item['key']);
if ($this->table2[$idx] === null) { $this->table2[$idx] = $item; $this->count++; return; }
// Kick out existing item $temp = $this->table2[$idx]; $this->table2[$idx] = $item; $item = $temp; $currentTable = 1; }
$kicks++; }
// Rehash if too many kicks $this->rehash(); $this->set($key, $value); }
public function get(string $key): mixed { $idx1 = $this->hash1($key); if ($this->table1[$idx1] !== null && $this->table1[$idx1]['key'] === $key) { return $this->table1[$idx1]['value']; }
$idx2 = $this->hash2($key); if ($this->table2[$idx2] !== null && $this->table2[$idx2]['key'] === $key) { return $this->table2[$idx2]['value']; }
return null; }
private function rehash(): void { $oldTable1 = $this->table1; $oldTable2 = $this->table2;
$this->size *= 2; $this->table1 = array_fill(0, $this->size, null); $this->table2 = array_fill(0, $this->size, null); $this->count = 0;
foreach ($oldTable1 as $item) { if ($item !== null) { $this->set($item['key'], $item['value']); } }
foreach ($oldTable2 as $item) { if ($item !== null) { $this->set($item['key'], $item['value']); } } }}Hopscotch Hashing
Section titled “Hopscotch Hashing”Combines benefits of chaining and open addressing. Keeps entries within a “hop range” of their ideal position:
class HopscotchHashTable{ private array $table; private array $hopInfo; // Bitmap of nearby items private int $size; private int $hopRange = 32; // Neighborhood size
public function __construct(int $size = 100) { $this->size = $size; $this->table = array_fill(0, $size, null); $this->hopInfo = array_fill(0, $size, 0); }
private function hash(string $key): int { return abs(crc32($key) % $this->size); }
public function set(string $key, mixed $value): void { $idx = $this->hash($key);
// Find empty slot $emptyIdx = $this->findEmptySlot($idx);
if ($emptyIdx === false) { // Table too full, need to resize return; }
// Move empty slot into hop range if needed while ($emptyIdx - $idx >= $this->hopRange) { $emptyIdx = $this->moveCloser($idx, $emptyIdx); if ($emptyIdx === false) { return; } }
// Insert item $this->table[$emptyIdx] = ['key' => $key, 'value' => $value]; $this->hopInfo[$idx] |= (1 << ($emptyIdx - $idx)); }
private function findEmptySlot(int $start): int|false { for ($i = 0; $i < $this->size; $i++) { $idx = ($start + $i) % $this->size; if ($this->table[$idx] === null) { return $idx; } } return false; }
private function moveCloser(int $target, int $empty): int|false { // Implementation of repositioning algorithm // Simplified for brevity return false; }
public function get(string $key): mixed { $idx = $this->hash($key); $hopInfo = $this->hopInfo[$idx];
// Check all positions in hop range for ($i = 0; $i < $this->hopRange; $i++) { if ($hopInfo & (1 << $i)) { $checkIdx = ($idx + $i) % $this->size; if ($this->table[$checkIdx] !== null && $this->table[$checkIdx]['key'] === $key) { return $this->table[$checkIdx]['value']; } } }
return null; }}Distributed Hash Tables
Section titled “Distributed Hash Tables”When scaling applications beyond a single server, you’ll need to distribute data across multiple nodes. This is where distributed hash tables and consistent hashing become essential. Let’s explore how to hash data across servers while minimizing disruption when nodes are added or removed.
The Problem with Simple Modulo Hashing
Section titled “The Problem with Simple Modulo Hashing”The naive approach to distributing keys across N servers uses modulo:
function getServer(string $key, int $serverCount): int{ return abs(crc32($key)) % $serverCount;}
// With 3 servers:echo getServer('user_123', 3); // Server 0echo getServer('user_456', 3); // Server 1echo getServer('user_789', 3); // Server 2The problem: When you add or remove a server, almost ALL keys need to be remapped:
// Originally 3 servers$serverCount = 3;$keys = ['user_1', 'user_2', 'user_3', 'user_4', 'user_5'];
foreach ($keys as $key) { $original = abs(crc32($key)) % 3; $afterAdd = abs(crc32($key)) % 4; // Added 1 server
if ($original !== $afterAdd) { echo "$key moved from server $original to $afterAdd\n"; }}
// Output: Most keys move! 🚨// user_1 moved from server 2 to 1// user_2 moved from server 0 to 3// user_3 moved from server 1 to 2// ... 75% of keys need to be moved!With modulo hashing, adding one server to a 3-server cluster requires moving 75% of all cached data. This causes a cache stampede that can take down your application.
Consistent Hashing Solution
Section titled “Consistent Hashing Solution”Consistent hashing solves this by arranging servers on a virtual ring (0 to 2³²-1). When you add or remove a server, only K/N keys need to move (where K is total keys, N is total servers).
How It Works
Section titled “How It Works”- Hash Ring: Imagine a circle with positions from 0 to 2³²-1
- Server Placement: Hash each server name onto the ring
- Key Placement: Hash each key onto the ring
- Lookup: To find which server stores a key, move clockwise from the key’s position until you find a server
Visual representation:
0/2³² | [Server C] / \ / \ user_123 [Server A] | | | user_456[Server B] | | | user_789 / \ / \/ 180°Basic Consistent Hash Implementation
Section titled “Basic Consistent Hash Implementation”class ConsistentHash{ private array $ring = []; private array $sortedKeys = []; private int $replicas;
public function __construct(int $replicas = 150) { $this->replicas = $replicas; // Virtual nodes per physical node }
public function addNode(string $node): void { // Add multiple virtual nodes for better distribution for ($i = 0; $i < $this->replicas; $i++) { $hash = crc32($node . ':' . $i); $this->ring[$hash] = $node; }
// Keep sorted for binary search $this->sortedKeys = array_keys($this->ring); sort($this->sortedKeys); }
public function removeNode(string $node): void { for ($i = 0; $i < $this->replicas; $i++) { $hash = crc32($node . ':' . $i); unset($this->ring[$hash]); }
$this->sortedKeys = array_keys($this->ring); sort($this->sortedKeys); }
public function getNode(string $key): ?string { if (empty($this->ring)) { return null; }
$hash = crc32($key);
// Binary search for the first node >= hash $idx = $this->findNode($hash);
return $this->ring[$this->sortedKeys[$idx]]; }
private function findNode(int $hash): int { // Binary search for first position >= hash $left = 0; $right = count($this->sortedKeys) - 1;
// If hash is larger than largest key, wrap around if ($hash > $this->sortedKeys[$right]) { return 0; }
while ($left < $right) { $mid = (int)(($left + $right) / 2);
if ($this->sortedKeys[$mid] < $hash) { $left = $mid + 1; } else { $right = $mid; } }
return $left; }
public function getNodes(): array { return array_unique(array_values($this->ring)); }
public function getDistribution(array $keys): array { $distribution = [];
foreach ($keys as $key) { $node = $this->getNode($key); $distribution[$node] = ($distribution[$node] ?? 0) + 1; }
return $distribution; }}Using Consistent Hashing
Section titled “Using Consistent Hashing”$ch = new ConsistentHash(replicas: 150);
// Add servers$ch->addNode('server-1');$ch->addNode('server-2');$ch->addNode('server-3');
// Distribute keys$keys = [];for ($i = 0; $i < 1000; $i++) { $keys[] = "user_$i";}
// Check distribution before adding server$beforeDist = $ch->getDistribution($keys);print_r($beforeDist);// server-1: 334 keys// server-2: 333 keys// server-3: 333 keys ← Pretty balanced!
// Add a new server$ch->addNode('server-4');
// Check distribution after$afterDist = $ch->getDistribution($keys);print_r($afterDist);// server-1: 251 keys// server-2: 250 keys// server-3: 250 keys// server-4: 249 keys
// Count how many keys moved$moved = 0;foreach ($keys as $key) { $before = $ch->getNode($key); // Would need to track original // With consistent hashing: only ~250 keys moved (25%) // With modulo: ~750 keys would move (75%)!}Virtual Nodes (Replicas)
Section titled “Virtual Nodes (Replicas)”Why do we create 150 virtual nodes per physical node? Better distribution!
function testDistribution(int $replicas): void{ $ch = new ConsistentHash($replicas); $ch->addNode('server-1'); $ch->addNode('server-2'); $ch->addNode('server-3');
$keys = array_map(fn($i) => "key_$i", range(1, 10000)); $dist = $ch->getDistribution($keys);
echo "Replicas: $replicas\n"; foreach ($dist as $node => $count) { $percent = ($count / 10000) * 100; echo " $node: $count keys (" . number_format($percent, 1) . "%)\n"; } echo "\n";}
// Compare different replica countstestDistribution(1); // Poor distribution// server-1: 8234 keys (82.3%) 🚨// server-2: 891 keys (8.9%)// server-3: 875 keys (8.8%)
testDistribution(10); // Better but still uneven// server-1: 4123 keys (41.2%)// server-2: 3456 keys (34.6%)// server-3: 2421 keys (24.2%)
testDistribution(150); // Good distribution!// server-1: 3341 keys (33.4%) ✅// server-2: 3330 keys (33.3%)// server-3: 3329 keys (33.3%)More virtual nodes = better load distribution, but slower lookups.
Sweet spot: 100-200 replicas per node.
Production-Ready Implementation
Section titled “Production-Ready Implementation”class ProductionConsistentHash{ private array $ring = []; private array $sortedKeys = []; private array $nodes = []; private int $replicas; private string $hashAlgorithm;
public function __construct( int $replicas = 150, string $hashAlgorithm = 'crc32' ) { $this->replicas = $replicas; $this->hashAlgorithm = $hashAlgorithm; }
private function hash(string $value): int { return match($this->hashAlgorithm) { 'crc32' => abs(crc32($value)), 'md5' => abs((int)hexdec(substr(md5($value), 0, 8))), 'fnv1a' => $this->fnv1a($value), default => abs(crc32($value)) }; }
private function fnv1a(string $value): int { $hash = 2166136261; for ($i = 0; $i < strlen($value); $i++) { $hash ^= ord($value[$i]); $hash = ($hash * 16777619) & 0xFFFFFFFF; } return abs($hash); }
public function addNode(string $node, int $weight = 1): void { $this->nodes[$node] = $weight;
// More replicas for higher weight nodes $nodeReplicas = $this->replicas * $weight;
for ($i = 0; $i < $nodeReplicas; $i++) { $hash = $this->hash($node . ':' . $i); $this->ring[$hash] = $node; }
$this->sortedKeys = array_keys($this->ring); sort($this->sortedKeys); }
public function removeNode(string $node): void { if (!isset($this->nodes[$node])) { return; }
$weight = $this->nodes[$node]; $nodeReplicas = $this->replicas * $weight;
for ($i = 0; $i < $nodeReplicas; $i++) { $hash = $this->hash($node . ':' . $i); unset($this->ring[$hash]); }
unset($this->nodes[$node]); $this->sortedKeys = array_keys($this->ring); sort($this->sortedKeys); }
public function getNode(string $key): ?string { if (empty($this->ring)) { return null; }
$hash = $this->hash($key); $idx = $this->findNode($hash);
return $this->ring[$this->sortedKeys[$idx]]; }
public function getNodes(string $key, int $count): array { if (empty($this->ring) || $count <= 0) { return []; }
$hash = $this->hash($key); $nodes = []; $seenNodes = []; $idx = $this->findNode($hash);
while (count($nodes) < $count && count($seenNodes) < count($this->nodes)) { $node = $this->ring[$this->sortedKeys[$idx]];
if (!isset($seenNodes[$node])) { $nodes[] = $node; $seenNodes[$node] = true; }
$idx = ($idx + 1) % count($this->sortedKeys); }
return $nodes; }
private function findNode(int $hash): int { $left = 0; $right = count($this->sortedKeys) - 1;
if ($hash > $this->sortedKeys[$right]) { return 0; }
while ($left < $right) { $mid = (int)(($left + $right) / 2);
if ($this->sortedKeys[$mid] < $hash) { $left = $mid + 1; } else { $right = $mid; } }
return $left; }
public function getStats(): array { return [ 'nodes' => count($this->nodes), 'virtual_nodes' => count($this->ring), 'replicas_per_node' => $this->replicas, 'hash_algorithm' => $this->hashAlgorithm ]; }}Real-World Use Cases
Section titled “Real-World Use Cases”1. Redis Cluster Sharding
Section titled “1. Redis Cluster Sharding”class RedisCluster{ private ProductionConsistentHash $hash; private array $connections = [];
public function __construct(array $servers) { $this->hash = new ProductionConsistentHash(replicas: 160);
foreach ($servers as $server) { $this->hash->addNode($server); $this->connections[$server] = new Redis(); $this->connections[$server]->connect($server, 6379); } }
public function get(string $key): mixed { $server = $this->hash->getNode($key); return $this->connections[$server]->get($key); }
public function set(string $key, mixed $value, int $ttl = 3600): bool { $server = $this->hash->getNode($key); return $this->connections[$server]->setex($key, $ttl, $value); }
public function delete(string $key): bool { $server = $this->hash->getNode($key); return $this->connections[$server]->del($key) > 0; }
// Replicate to multiple nodes for redundancy public function setReplicated(string $key, mixed $value, int $replicas = 2): bool { $servers = $this->hash->getNodes($key, $replicas); $success = true;
foreach ($servers as $server) { $result = $this->connections[$server]->set($key, $value); $success = $success && $result; }
return $success; }
public function addServer(string $server): void { $this->hash->addNode($server); $this->connections[$server] = new Redis(); $this->connections[$server]->connect($server, 6379);
// In production, you'd migrate keys here echo "Added $server - only ~" . (100 / count($this->connections)) . "% of keys need migration\n"; }}
// Usage$cluster = new RedisCluster(['redis-1', 'redis-2', 'redis-3']);$cluster->set('user:123:profile', json_encode(['name' => 'Alice']));$profile = $cluster->get('user:123:profile');
// Add server dynamically - minimal disruption$cluster->addServer('redis-4');2. Database Sharding
Section titled “2. Database Sharding”class ShardedDatabase{ private ProductionConsistentHash $hash; private array $connections = [];
public function __construct(array $shardConfigs) { $this->hash = new ProductionConsistentHash(replicas: 200);
foreach ($shardConfigs as $name => $config) { $weight = $config['weight'] ?? 1; $this->hash->addNode($name, $weight);
$this->connections[$name] = new PDO( "mysql:host={$config['host']};dbname={$config['db']}", $config['user'], $config['pass'] ); } }
public function getConnection(string $shardKey): PDO { $shard = $this->hash->getNode($shardKey); return $this->connections[$shard]; }
public function insert(string $table, string $shardKey, array $data): bool { $db = $this->getConnection($shardKey);
$columns = implode(', ', array_keys($data)); $placeholders = implode(', ', array_fill(0, count($data), '?'));
$stmt = $db->prepare("INSERT INTO $table ($columns) VALUES ($placeholders)"); return $stmt->execute(array_values($data)); }
public function findByKey(string $table, string $shardKey, string $idColumn): ?array { $db = $this->getConnection($shardKey);
$stmt = $db->prepare("SELECT * FROM $table WHERE $idColumn = ?"); $stmt->execute([$shardKey]);
return $stmt->fetch(PDO::FETCH_ASSOC) ?: null; }}
// Usage with user_id as shard key$db = new ShardedDatabase([ 'shard-1' => ['host' => 'db1.example.com', 'db' => 'app', 'user' => 'root', 'pass' => 'secret', 'weight' => 2], 'shard-2' => ['host' => 'db2.example.com', 'db' => 'app', 'user' => 'root', 'pass' => 'secret', 'weight' => 1], 'shard-3' => ['host' => 'db3.example.com', 'db' => 'app', 'user' => 'root', 'pass' => 'secret', 'weight' => 1],]);
$userId = 'user_12345';$db->insert('users', $userId, [ 'user_id' => $userId, 'name' => 'Alice', 'email' => 'alice@example.com']);
$user = $db->findByKey('users', $userId, 'user_id');Comparison: Modulo vs Consistent Hashing
Section titled “Comparison: Modulo vs Consistent Hashing”Let’s compare how many keys need to be moved when adding a server:
function compareApproaches(int $originalServers, int $newServers, int $keyCount): void{ $keys = array_map(fn($i) => "key_$i", range(1, $keyCount));
// Modulo approach $moduloMoved = 0; foreach ($keys as $key) { $originalServer = abs(crc32($key)) % $originalServers; $newServer = abs(crc32($key)) % $newServers;
if ($originalServer !== $newServer) { $moduloMoved++; } }
// Consistent hashing $ch = new ConsistentHash(150); for ($i = 1; $i <= $originalServers; $i++) { $ch->addNode("server-$i"); }
$originalPlacement = []; foreach ($keys as $key) { $originalPlacement[$key] = $ch->getNode($key); }
$ch->addNode("server-" . $newServers);
$consistentMoved = 0; foreach ($keys as $key) { if ($originalPlacement[$key] !== $ch->getNode($key)) { $consistentMoved++; } }
// Results $moduloPercent = ($moduloMoved / $keyCount) * 100; $consistentPercent = ($consistentMoved / $keyCount) * 100;
echo "Adding 1 server to $originalServers servers ($keyCount keys):\n"; echo " Modulo: $moduloMoved keys moved (" . number_format($moduloPercent, 1) . "%)\n"; echo " Consistent: $consistentMoved keys moved (" . number_format($consistentPercent, 1) . "%)\n"; echo " Improvement: " . number_format($moduloPercent / $consistentPercent, 1) . "x fewer keys moved!\n\n";}
compareApproaches(3, 4, 10000);// Modulo: 7501 keys moved (75.0%)// Consistent: 2489 keys moved (24.9%)// Improvement: 3.0x fewer keys moved!
compareApproaches(10, 11, 10000);// Modulo: 9091 keys moved (90.9%)// Consistent: 909 keys moved (9.1%)// Improvement: 10.0x fewer keys moved!Key insight: With consistent hashing, only ~1/N keys move when adding a node (where N is the new server count). With modulo, almost ALL keys move!
Alternative: Rendezvous Hashing
Section titled “Alternative: Rendezvous Hashing”Rendezvous hashing (Highest Random Weight) is an alternative that’s simpler and provides even better distribution:
class RendezvousHash{ private array $nodes = [];
public function addNode(string $node): void { $this->nodes[] = $node; }
public function removeNode(string $node): void { $this->nodes = array_values( array_filter($this->nodes, fn($n) => $n !== $node) ); }
public function getNode(string $key): ?string { if (empty($this->nodes)) { return null; }
$maxScore = -1; $selectedNode = null;
foreach ($this->nodes as $node) { // Combine key and node, hash them $score = crc32($key . $node);
if ($score > $maxScore) { $maxScore = $score; $selectedNode = $node; } }
return $selectedNode; }}
// Usage$rh = new RendezvousHash();$rh->addNode('server-1');$rh->addNode('server-2');$rh->addNode('server-3');
echo $rh->getNode('user_123'); // server-2echo $rh->getNode('user_456'); // server-1Pros:
- Simpler implementation (no ring or sorting)
- Better load distribution
- Deterministic (no virtual nodes needed)
Cons:
- O(N) lookup time (must check all nodes)
- Slower than consistent hashing for many nodes
Use when: You have few nodes (< 20) and want perfect distribution.
Performance Comparison
Section titled “Performance Comparison”function benchmarkDistributedHashing(): void{ $nodes = ['server-1', 'server-2', 'server-3', 'server-4', 'server-5']; $keys = array_map(fn($i) => "key_$i", range(1, 10000));
// Consistent Hashing $ch = new ProductionConsistentHash(150); foreach ($nodes as $node) { $ch->addNode($node); }
$start = microtime(true); foreach ($keys as $key) { $ch->getNode($key); } $chTime = microtime(true) - $start;
// Rendezvous Hashing $rh = new RendezvousHash(); foreach ($nodes as $node) { $rh->addNode($node); }
$start = microtime(true); foreach ($keys as $key) { $rh->getNode($key); } $rhTime = microtime(true) - $start;
// Simple Modulo $start = microtime(true); foreach ($keys as $key) { abs(crc32($key)) % count($nodes); } $moduloTime = microtime(true) - $start;
echo "Lookup performance (10,000 keys, 5 nodes):\n"; echo " Modulo: " . number_format($moduloTime * 1000, 2) . "ms (fastest but breaks on resize)\n"; echo " Consistent: " . number_format($chTime * 1000, 2) . "ms (O(log N) per lookup)\n"; echo " Rendezvous: " . number_format($rhTime * 1000, 2) . "ms (O(N) per lookup)\n";}When to Use Distributed Hashing
Section titled “When to Use Distributed Hashing”Use Consistent Hashing when:
- ✅ You have distributed caching (Redis, Memcached)
- ✅ You need to shard databases across multiple servers
- ✅ Servers are added/removed dynamically
- ✅ You want to minimize cache invalidation
- ✅ You have many nodes (> 20)
Use Rendezvous Hashing when:
- ✅ You want perfect load distribution
- ✅ You have few nodes (< 20)
- ✅ Simpler implementation is preferred
- ✅ Lookup speed is not critical
Use Simple Modulo when:
- ✅ Node count NEVER changes
- ✅ Full cache invalidation is acceptable
- ✅ Maximum performance is critical
Performance Benchmarks: Collision Strategies
Section titled “Performance Benchmarks: Collision Strategies”Let’s benchmark different collision strategies to see which performs best under various conditions:
class CollisionBenchmark{ public function compareStrategies(): void { $sizes = [1000, 10000, 50000]; $loadFactors = [0.5, 0.75, 0.9];
foreach ($sizes as $size) { echo "\n=== Testing with $size items ===\n";
foreach ($loadFactors as $loadFactor) { $capacity = (int)($size / $loadFactor);
echo "\nLoad Factor: $loadFactor\n"; echo str_repeat('-', 50) . "\n";
// Generate test data $keys = $this->generateKeys($size); $values = range(1, $size);
// Test Chaining $chaining = new HashTableChaining($capacity); $start = microtime(true); foreach ($keys as $i => $key) { $chaining->set($key, $values[$i]); } $chainingInsert = microtime(true) - $start;
$start = microtime(true); foreach ($keys as $key) { $chaining->get($key); } $chainingSearch = microtime(true) - $start;
// Test Linear Probing $linear = new HashTableLinearProbing($capacity); $start = microtime(true); foreach ($keys as $i => $key) { $linear->set($key, $values[$i]); } $linearInsert = microtime(true) - $start;
$start = microtime(true); foreach ($keys as $key) { $linear->get($key); } $linearSearch = microtime(true) - $start;
// Test Robin Hood $robinHood = new RobinHoodHashTable($capacity); $start = microtime(true); foreach ($keys as $i => $key) { $robinHood->set($key, $values[$i]); } $robinInsert = microtime(true) - $start;
$start = microtime(true); foreach ($keys as $key) { $robinHood->get($key); } $robinSearch = microtime(true) - $start;
// Display results printf("Chaining: Insert: %.4fs, Search: %.4fs\n", $chainingInsert, $chainingSearch); printf("Linear Probe: Insert: %.4fs, Search: %.4fs\n", $linearInsert, $linearSearch); printf("Robin Hood: Insert: %.4fs, Search: %.4fs\n", $robinInsert, $robinSearch); } } }
private function generateKeys(int $count): array { $keys = []; for ($i = 0; $i < $count; $i++) { $keys[] = 'key_' . bin2hex(random_bytes(8)); } return $keys; }
public function memoryComparison(): void { $size = 10000; $keys = $this->generateKeys($size);
echo "\n=== Memory Usage Comparison ===\n\n";
// Chaining $memBefore = memory_get_usage(); $chaining = new HashTableChaining($size); foreach ($keys as $i => $key) { $chaining->set($key, $i); } $chainingMem = memory_get_usage() - $memBefore;
// Linear Probing $memBefore = memory_get_usage(); $linear = new HashTableLinearProbing($size); foreach ($keys as $i => $key) { $linear->set($key, $i); } $linearMem = memory_get_usage() - $memBefore;
// Robin Hood $memBefore = memory_get_usage(); $robin = new RobinHoodHashTable($size); foreach ($keys as $i => $key) { $robin->set($key, $i); } $robinMem = memory_get_usage() - $memBefore;
printf("Chaining: %s\n", $this->formatBytes($chainingMem)); printf("Linear Probe: %s\n", $this->formatBytes($linearMem)); printf("Robin Hood: %s\n", $this->formatBytes($robinMem)); }
private function formatBytes(int $bytes): string { $units = ['B', 'KB', 'MB', 'GB']; $i = 0; while ($bytes >= 1024 && $i < count($units) - 1) { $bytes /= 1024; $i++; } return round($bytes, 2) . ' ' . $units[$i]; }}
// Run benchmarks$benchmark = new CollisionBenchmark();$benchmark->compareStrategies();$benchmark->memoryComparison();PHP SPL Implementations
Section titled “PHP SPL Implementations”Using SplObjectStorage as Hash Table
Section titled “Using SplObjectStorage as Hash Table”PHP’s SPL provides ready-to-use hash table implementations:
class SPLHashExamples{ /** * SplObjectStorage - hash table for objects */ public function objectHashTable(): void { $storage = new SplObjectStorage();
// Create objects $user1 = new stdClass(); $user1->name = 'Alice'; $user1->email = 'alice@example.com';
$user2 = new stdClass(); $user2->name = 'Bob'; $user2->email = 'bob@example.com';
// Store objects with associated data $storage[$user1] = ['role' => 'admin', 'lastLogin' => time()]; $storage[$user2] = ['role' => 'user', 'lastLogin' => time() - 3600];
// Retrieve echo $storage[$user1]['role']; // admin
// Check existence if ($storage->contains($user1)) { echo "User exists\n"; }
// Iterate foreach ($storage as $user) { $data = $storage[$user]; echo "{$user->name}: {$data['role']}\n"; } }
/** * Custom hash table using SplFixedArray */ public function fixedArrayHashTable(): void { $size = 1000; $table = new SplFixedArray($size);
$hash = function($key) use ($size) { return abs(crc32($key) % $size); };
// Set value $set = function($key, $value) use ($table, $hash) { $idx = $hash($key);
if (!isset($table[$idx])) { $table[$idx] = []; }
$table[$idx][$key] = $value; };
// Get value $get = function($key) use ($table, $hash) { $idx = $hash($key);
if (!isset($table[$idx])) { return null; }
return $table[$idx][$key] ?? null; };
// Usage $set('name', 'John'); $set('age', 30);
echo $get('name'); // John echo $get('age'); // 30 }
/** * Weak reference hash table */ public function weakReferenceHash(): void { if (!class_exists('WeakMap')) { echo "WeakMap not available (PHP 8.0+)\n"; return; }
$map = new WeakMap();
$obj1 = new stdClass(); $obj2 = new stdClass();
$map[$obj1] = 'data for obj1'; $map[$obj2] = 'data for obj2';
echo $map[$obj1]; // 'data for obj1'
unset($obj1); // Object and its entry are garbage collected }}
$examples = new SPLHashExamples();$examples->objectHashTable();$examples->fixedArrayHashTable();$examples->weakReferenceHash();Security Considerations
Section titled “Security Considerations”Hash Flooding Attacks
Section titled “Hash Flooding Attacks”Protect against algorithmic complexity attacks where attackers craft keys that all hash to the same bucket:
class SecureHashTable{ private array $table; private int $size; private string $randomSeed; private int $maxChainLength = 8;
public function __construct(int $size = 100) { $this->size = $size; $this->table = array_fill(0, $size, []);
// Random seed to prevent hash prediction $this->randomSeed = bin2hex(random_bytes(16)); }
/** * Secure hash function with random seed */ private function hash(string $key): int { // Use random seed to make hash unpredictable $hash = hash_hmac('sha256', $key, $this->randomSeed); return abs(hexdec(substr($hash, 0, 8)) % $this->size); }
public function set(string $key, mixed $value): void { $index = $this->hash($key);
// Check chain length to prevent DOS if (count($this->table[$index]) >= $this->maxChainLength) { $this->resize(); $index = $this->hash($key); }
// Check if key exists foreach ($this->table[$index] as &$pair) { if ($pair['key'] === $key) { $pair['value'] = $value; return; } }
// Add new entry $this->table[$index][] = ['key' => $key, 'value' => $value]; }
public function get(string $key): mixed { $index = $this->hash($key);
foreach ($this->table[$index] as $pair) { if ($pair['key'] === $key) { return $pair['value']; } }
return null; }
private function resize(): void { $oldTable = $this->table; $this->size *= 2; $this->table = array_fill(0, $this->size, []);
// Rehash all entries foreach ($oldTable as $bucket) { foreach ($bucket as $pair) { $this->set($pair['key'], $pair['value']); } } }
/** * Rate limiting for set operations */ private array $setAttempts = [];
public function setWithRateLimit( string $clientId, string $key, mixed $value, int $maxOps = 1000, int $windowSec = 60 ): bool { $now = time();
if (!isset($this->setAttempts[$clientId])) { $this->setAttempts[$clientId] = ['count' => 0, 'window' => $now]; }
$clientData = &$this->setAttempts[$clientId];
// Reset window if expired if ($now - $clientData['window'] > $windowSec) { $clientData = ['count' => 0, 'window' => $now]; }
// Check rate limit if ($clientData['count'] >= $maxOps) { throw new Exception("Rate limit exceeded for client: $clientId"); }
$clientData['count']++; $this->set($key, $value);
return true; }}Cryptographic Hash Functions for Sensitive Data
Section titled “Cryptographic Hash Functions for Sensitive Data”When storing sensitive data, use cryptographic hashing and encryption:
class CryptographicHashTable{ private array $table; private int $size;
public function __construct(int $size = 100) { $this->size = $size; $this->table = array_fill(0, $size, []); }
/** * Use cryptographic hash for sensitive keys */ private function hash(string $key): int { $hash = hash('sha256', $key); return abs(hexdec(substr($hash, 0, 8)) % $this->size); }
/** * Store sensitive data with encryption */ public function setSecure(string $key, string $sensitiveValue, string $encryptionKey): void { // Encrypt value $iv = random_bytes(16); $encrypted = openssl_encrypt( $sensitiveValue, 'aes-256-cbc', $encryptionKey, 0, $iv );
$index = $this->hash($key);
$this->table[$index][] = [ 'key_hash' => hash('sha256', $key), // Don't store actual key 'value' => base64_encode($encrypted), 'iv' => base64_encode($iv) ]; }
/** * Retrieve and decrypt sensitive data */ public function getSecure(string $key, string $encryptionKey): ?string { $index = $this->hash($key); $keyHash = hash('sha256', $key);
foreach ($this->table[$index] as $pair) { if ($pair['key_hash'] === $keyHash) { $decrypted = openssl_decrypt( base64_decode($pair['value']), 'aes-256-cbc', $encryptionKey, 0, base64_decode($pair['iv']) );
return $decrypted !== false ? $decrypted : null; } }
return null; }}
// Usage$secureTable = new CryptographicHashTable();$encryptionKey = hash('sha256', 'your-secret-key', true);
$secureTable->setSecure('user:123:ssn', '123-45-6789', $encryptionKey);$ssn = $secureTable->getSecure('user:123:ssn', $encryptionKey);Complexity Analysis
Section titled “Complexity Analysis”| Operation | Average | Worst Case |
|---|---|---|
| Insert | O(1) | O(n)* |
| Search | O(1) | O(n)* |
| Delete | O(1) | O(n)* |
| Space | O(n) | O(n) |
*Worst case happens with many collisions or poor hash function
| Collision Strategy | Insert | Search | Delete | Memory | Best For |
|---|---|---|---|---|---|
| Chaining | O(1) avg | O(1) avg | O(1) avg | High | General use |
| Linear Probing | O(1) avg | O(1) avg | O(1) avg | Low | Cache-friendly |
| Quadratic Probing | O(1) avg | O(1) avg | O(1) avg | Low | Better clustering |
| Double Hashing | O(1) avg | O(1) avg | O(1) avg | Low | Uniform distribution |
| Robin Hood | O(1) avg | O(1) avg | O(1) avg | Low | Bounded variance |
| Cuckoo | O(1) worst | O(1) | O(1) | Medium | Guaranteed O(1) lookup |
Practice Exercises
Section titled “Practice Exercises”Test your understanding with these hands-on challenges:
Exercise 1: Implement Set Data Structure
Section titled “Exercise 1: Implement Set Data Structure”Goal: Build a Set (unique values only) using your hash table implementation
Requirements:
- Create a
Setclass that stores unique values - Implement
add(),has(),delete(), andsize()methods - Duplicates should be automatically ignored
- Should handle any data type (strings, integers, objects)
Starter code:
class Set{ private HashTableChaining $table;
public function __construct() { $this->table = new HashTableChaining(); }
public function add(mixed $value): void { // Your implementation here }
public function has(mixed $value): bool { // Your implementation here }
public function delete(mixed $value): bool { // Your implementation here }
public function size(): int { // Your implementation here }}Validation:
$set = new Set();$set->add(1);$set->add(2);$set->add(1); // Duplicate - should be ignored$set->add(3);
echo $set->size(); // Should output: 3echo $set->has(2) ? 'true' : 'false'; // Should output: true$set->delete(2);echo $set->has(2) ? 'true' : 'false'; // Should output: falseExercise 2: Group Anagrams
Section titled “Exercise 2: Group Anagrams”Goal: Group words that are anagrams using a hash table in O(n × m) time where n is word count and m is average word length
Requirements:
- Take an array of strings
- Return groups of anagrams (words with same letters in different order)
- Use sorted characters as the hash key
- Handle case sensitivity appropriately
Starter code:
function groupAnagrams(array $words): array{ $groups = new HashTableChaining();
foreach ($words as $word) { // Sort characters to create key $key = // Your code here
// Get existing group or create new one $group = // Your code here
// Add word to group // Your code here
// Store back in hash table // Your code here }
// Convert hash table to array of groups // Your code here}Validation:
$words = ['eat', 'tea', 'tan', 'ate', 'nat', 'bat'];$result = groupAnagrams($words);print_r($result);
// Expected output (order may vary):// [// ['eat', 'tea', 'ate'],// ['tan', 'nat'],// ['bat']// ]Exercise 3: LRU Cache
Section titled “Exercise 3: LRU Cache”Goal: Implement an LRU (Least Recently Used) cache using hash table + doubly linked list
Requirements:
- Fixed capacity cache
get(key)returns value or null, marks as recently usedput(key, value)inserts/updates, marks as recently used- When full, evict least recently used item
- Both operations should be O(1)
Hint: Use hash table for O(1) lookup and doubly linked list for O(1) eviction
Starter code:
class LRUCache{ private HashTableChaining $cache; private array $accessOrder; // Track access order private int $capacity;
public function __construct(int $capacity) { $this->capacity = $capacity; $this->cache = new HashTableChaining(); $this->accessOrder = []; }
public function get(string $key): mixed { // Your implementation here // 1. Check if key exists // 2. If yes, update access order and return value // 3. If no, return null }
public function put(string $key, mixed $value): void { // Your implementation here // 1. Check if at capacity and key doesn't exist // 2. If at capacity, remove LRU item // 3. Add/update key-value pair // 4. Update access order }}Validation:
$cache = new LRUCache(2);
$cache->put('a', 1);$cache->put('b', 2);echo $cache->get('a'); // Returns 1
$cache->put('c', 3); // Evicts key 'b'echo $cache->get('b'); // Returns null (evicted)
$cache->put('d', 4); // Evicts key 'a'echo $cache->get('a'); // Returns null (evicted)echo $cache->get('c'); // Returns 3echo $cache->get('d'); // Returns 4Exercise 4: First Unique Character
Section titled “Exercise 4: First Unique Character”Goal: Find the first non-repeating character in a string using hash table
Requirements:
- Return index of first character that appears only once
- If no unique character exists, return -1
- Should be O(n) time complexity
Starter code:
function firstUnique(string $s): int{ // Your implementation using hash table}Validation:
echo firstUnique("leetcode"); // 0 (l)echo firstUnique("loveleetcode"); // 2 (v)echo firstUnique("aabb"); // -1 (no unique char)Key Takeaways
Section titled “Key Takeaways”Congratulations! You’ve mastered one of computer science’s most important data structures. Here’s what you now know:
Core Concepts
Section titled “Core Concepts”- ✅ Hash tables provide O(1) average-case operations for insert, search, and delete
- ✅ Hash functions convert keys to array indices deterministically
- ✅ Collisions are inevitable - you learned two main strategies to handle them
- ✅ Load factor (entries/size) determines performance and when to resize
Collision Handling
Section titled “Collision Handling”- ✅ Separate chaining uses linked lists/arrays at each index - simple and effective
- ✅ Open addressing (linear probing, quadratic probing, double hashing) saves memory
- ✅ Robin Hood hashing reduces variance in probe lengths
- ✅ Cuckoo hashing guarantees O(1) worst-case lookups
- ✅ Hopscotch hashing keeps entries within “hop range”
Distributed Hash Tables
Section titled “Distributed Hash Tables”- ✅ Consistent hashing minimizes cache invalidation when adding/removing servers
- ✅ Virtual nodes (replicas) improve load distribution across the hash ring
- ✅ Rendezvous hashing provides simpler alternative with perfect distribution
- ✅ Only ~1/N keys move when adding nodes (vs 75%+ with simple modulo)
Hash Function Design
Section titled “Hash Function Design”- ✅ Good hash functions are fast, deterministic, and distribute uniformly
- ✅ Division method: Simple modulo operation
- ✅ Multiplication method: Uses golden ratio for better distribution
- ✅ Polynomial rolling hash: Best for strings, minimal collisions
- ✅ FNV-1a: Industry standard for non-cryptographic hashing
Real-World Applications
Section titled “Real-World Applications”- ✅ PHP arrays ARE hash tables - now you understand what powers them
- ✅ Build caches with O(1) lookups
- ✅ Count frequencies in O(n) time instead of O(n²)
- ✅ Detect duplicates efficiently
- ✅ Solve classic problems like Two Sum in O(n)
- ✅ Redis cluster sharding with consistent hashing
- ✅ Database sharding across multiple servers
- ✅ Load balancing with minimal disruption on node changes
Security & Performance
Section titled “Security & Performance”- ✅ Protect against hash flooding DoS attacks with random seeds
- ✅ Use cryptographic hash functions for sensitive data
- ✅ Benchmark different strategies for your use case
- ✅ Leverage PHP’s SPL (SplObjectStorage, WeakMap) for specialized needs
When to Use Hash Tables
Section titled “When to Use Hash Tables”Use hash tables when you need:
- Fast key-value lookups (O(1) vs O(log n) for BST)
- Counting/frequency analysis
- Duplicate detection
- Set operations (union, intersection)
- Caching and memoization
- Distributing data across multiple servers (consistent hashing)
Avoid hash tables when:
- You need sorted data (use trees instead)
- Memory is severely constrained
- Keys don’t hash well (custom objects without good hash functions)
- You need range queries (use B-trees or sorted arrays)
What’s Next
Section titled “What’s Next”In Chapter 14: String Search Algorithms, you’ll learn pattern matching techniques including:
- Naive string search
- Knuth-Morris-Pratt (KMP) algorithm
- Boyer-Moore algorithm
- Rabin-Karp with rolling hashes (uses what you learned here!)
These algorithms are essential for text processing, search engines, and DNA sequence matching.
💻 Code Samples
Section titled “💻 Code Samples”All code examples from this chapter are available in the GitHub repository:
Clone the repository to run examples:
git clone https://github.com/dalehurley/codewithphp.gitcd codewithphp/code/php-algorithms/chapter-13php 01-*.phpContinue to Chapter 14: String Search Algorithms.