15: Structured Outputs with JSON
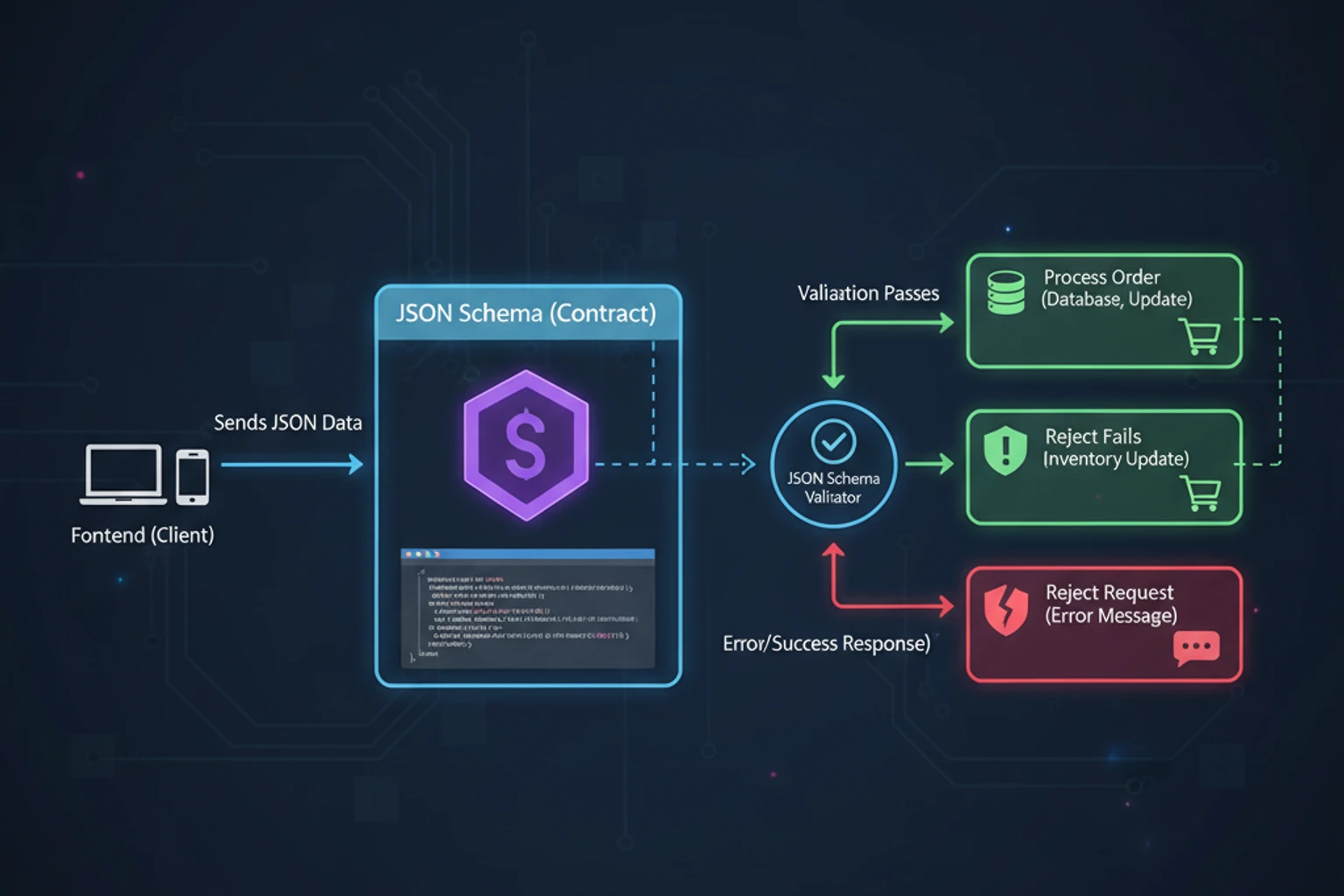
Chapter 15: Structured Outputs with JSON
Section titled “Chapter 15: Structured Outputs with JSON”Overview
Section titled “Overview”Getting reliable, structured data from AI is critical for production applications. In this chapter, you’ll master techniques for extracting consistent JSON responses from Claude, validating outputs, handling edge cases, and building robust data extraction pipelines.
You’ll learn schema definition strategies, validation patterns, error recovery techniques, and how to build data extraction systems that work reliably at scale. We’ll cover everything from basic structured output extraction to advanced batch processing and streaming implementations.
By the end of this chapter, you’ll have built a complete data extraction system that can reliably extract structured information from unstructured text, validate it against schemas, handle errors gracefully, and process multiple items efficiently.
Prerequisites
Section titled “Prerequisites”Before starting this chapter, you should have:
- ✓ JSON and schema knowledge (JSON Schema standard)
- ✓ Data validation experience in PHP
- ✓ Completed Chapter 00 and Chapter 05
- ✓ Understanding of type systems and validation
- ✓ PHP 8.4+ installed and working
- ✓ Composer for dependency management
Estimated Time: 45-60 minutes
What You’ll Build
Section titled “What You’ll Build”By the end of this chapter, you will have created:
- A
SchemaExtractorclass with retry logic and schema validation - Pre-built schema definitions for common data types (person, product, event, article, transaction)
- A
CustomValidatorclass for business logic validation beyond JSON Schema - A
BatchExtractorclass for processing multiple items efficiently - A
StreamingExtractorclass for handling large outputs - Complete extraction pipeline examples for real-world use cases
- Production-ready error handling and validation layers
You’ll have a complete understanding of how to extract structured data from Claude responses, validate outputs, handle edge cases, and build robust data extraction systems.
Objectives
Section titled “Objectives”By completing this chapter, you will:
- Understand how to define JSON schemas for structured output extraction
- Create reusable extraction classes with retry logic and validation
- Implement schema validation using JSON Schema and custom validators
- Build pre-built schemas for common data extraction use cases
- Master batch processing and streaming for large-scale extraction
- Apply error recovery techniques and fallback strategies
- Design production-ready extraction pipelines with multiple validation layers
Install Required Libraries
Section titled “Install Required Libraries”composer require claude-php/Claude-PHP-SDKcomposer require justinrainbow/json-schemaStep 1: Basic Structured Output (~10 min)
Section titled “Step 1: Basic Structured Output (~10 min)”Create a simple function that extracts structured contact information from unstructured text using Claude. We’ll show both the native API feature (recommended) and prompt-based extraction (fallback for older models).
Actions
Section titled “Actions”- Use Claude’s native
response_formatparameter for guaranteed JSON structure (Sonnet 4.5+) - Create a fallback function using prompt-based extraction for older models
- Parse the response to extract JSON from markdown code blocks or plain text
- Validate the JSON and handle parsing errors gracefully
- Test with sample data to verify the extraction works correctly
<?phpdeclare(strict_types=1);
require __DIR__ . '/../vendor/autoload.php';
use ClaudePhp\ClaudePhp;
$client = new ClaudePhp( apiKey: $_ENV['ANTHROPIC_API_KEY']);
function extractContactInfo(string $text, ClaudePhp $client, bool $useNativeFormat = true): array{ $schema = [ 'type' => 'object', 'properties' => [ 'name' => [ 'type' => 'string', 'description' => 'Full name of the contact' ], 'email' => [ 'type' => 'string', 'format' => 'email', 'description' => 'Email address' ], 'phone' => [ 'type' => 'string', 'description' => 'Phone number' ], 'company' => [ 'type' => 'string', 'description' => 'Company name' ], 'title' => [ 'type' => 'string', 'description' => 'Job title' ] ], 'required' => ['name'], 'additionalProperties' => false ];
// Method 1: Native structured output (recommended for Sonnet 4.5+) if ($useNativeFormat) { try { $response = $client->messages()->create([ 'model' => 'claude-sonnet-4-5', 'max_tokens' => 1024, 'messages' => [ [ 'role' => 'user', 'content' => "Extract contact information from this text:\n\n{$text}" ) ], responseFormat: [ 'type' => 'json_schema', 'json_schema' => [ 'name' => 'contact_extraction', 'strict' => true, 'schema' => $schema ] ] );
if (empty($response->content) || !isset($response->content[0]->text) { throw new \RuntimeException('Empty response from Claude API'); }
// Native format returns valid JSON directly $data = json_decode($response->content[0]->text, true);
if (json_last_error() !== JSON_ERROR_NONE) { throw new \RuntimeException('Invalid JSON response: ' . json_last_error_msg()); }
return $data; } catch (\Exception $e) { // Fallback to prompt-based if native format fails if (str_contains($e->getMessage(), 'response_format') || str_contains($e->getMessage(), 'not supported')) { // Model doesn't support native structured output, use fallback return extractContactInfoPromptBased($text, $client, $schema); } throw $e; } }
// Method 2: Prompt-based extraction (fallback for older models) return extractContactInfoPromptBased($text, $client, $schema);}
function extractContactInfoPromptBased(string $text, ClaudePhp $client, array $schema): array{ $schema_json = json_encode($schema, JSON_PRETTY_PRINT);
$prompt = <<<PROMPTExtract contact information from this text and return as JSON matching this schema:
Schema: {$schema_json}
Text: {$text}
Return ONLY valid JSON matching the schema. Use null for missing fields.PROMPT;
$response = $client->messages()->create([ 'model' => 'claude-sonnet-4-5', 'max_tokens' => 1024, 'temperature' => 0.3, 'messages' => [ [ 'role' => 'user', 'content' => $prompt ) ] );
if (empty($response->content) || !isset($response->content[0]->text) { throw new \RuntimeException('Empty response from Claude API'); }
$responseText = $response->content[0]->text;
// Extract JSON from response if (preg_match('/```json\s*(\{.*?\})\s*```/s', $responseText, $matches)) { $responseText = $matches[1]; } elseif (preg_match('/(\{.*?\})/s', $responseText, $matches)) { $responseText = $matches[1]; }
$data = json_decode($responseText, true);
if (json_last_error() !== JSON_ERROR_NONE) { throw new \RuntimeException('Invalid JSON response: ' . json_last_error_msg()); }
return $data;}
// Example usage$businessCard = <<<TEXTDr. Sarah JohnsonChief Technology OfficerTechCorp Industriessarah.johnson@techcorp.com+1 (555) 123-4567TEXT;
$contact = extractContactInfo($businessCard, $client);echo json_encode($contact, JSON_PRETTY_PRINT) . "\n";Expected Result
Section titled “Expected Result”{ "name": "Dr. Sarah Johnson", "email": "sarah.johnson@techcorp.com", "phone": "+1 (555) 123-4567", "company": "TechCorp Industries", "title": "Chief Technology Officer"}Why It Works
Section titled “Why It Works”Native Structured Output (Recommended):
Claude’s response_format parameter with json_schema type enforces strict JSON structure at the API level. When strict: true is set, Claude guarantees the response matches the schema exactly, eliminating parsing errors. This is the most reliable method for structured extraction and is available on Sonnet 4.5+ and Opus 4.1+ models.
Prompt-Based Extraction (Fallback):
For older models or when native format isn’t available, we use prompt-based extraction. The function defines a JSON schema in the prompt, and Claude extracts information to match it. The regex patterns extract JSON from markdown code blocks (if Claude wraps it) or directly from the response text. Lower temperature (0.3) increases consistency. The json_decode() function parses the JSON string into a PHP array, and we validate it using json_last_error().
When to Use Each Method:
- Native
response_format: Use for Sonnet 4.5+ and Opus 4.1+ models when you need guaranteed schema compliance - Prompt-based: Use for older models or when you need more flexibility in the extraction process
Troubleshooting
Section titled “Troubleshooting”- Error: “Invalid JSON response” — Claude may have returned explanatory text along with JSON. The regex patterns should handle this, but if it persists, check the raw response text to see what Claude actually returned. You can add
echo $responseText;before parsing to debug. - Error: “Empty response from Claude API” — This indicates the API call succeeded but returned no content. Check your API key and model name. Ensure you’re using a valid model like
claude-sonnet-4-5. - Missing fields — If some fields are missing, Claude will use
nullfor optional fields. Ensure required fields are marked in the schema. - Malformed JSON — If Claude returns JSON with syntax errors, the extraction will fail. Consider adding retry logic (shown in Step 2) to handle this.
- Variable scope issues — The function now accepts
$clientas a parameter instead of usingglobal. Make sure to pass the client when calling the function.
Step 2: Schema-Based Extraction Class (~15 min)
Section titled “Step 2: Schema-Based Extraction Class (~15 min)”Build a reusable SchemaExtractor class that handles extraction, validation, retry logic, and error recovery automatically.
Actions
Section titled “Actions”- Create the
SchemaExtractorclass with retry logic and schema validation - Implement JSON parsing that handles markdown code blocks and plain JSON
- Add schema validation using the JSON Schema validator library
- Create an
extractListmethod for extracting arrays of items
<?phpdeclare(strict_types=1);
namespace App\Extraction;
use ClaudePhp\ClaudePhp;use JsonSchema\Validator;use JsonSchema\Constraints\Constraint;
class SchemaExtractor{ public function __construct( private ClaudePhp $client, private int $maxRetries = 3 ) {}
/** * Extract structured data matching a JSON schema */ public function extract(string $input, array $schema, string $context = ''): array { $attempt = 0; $lastError = null;
while ($attempt < $this->maxRetries) { $attempt++;
try { $data = $this->attemptExtraction($input, $schema, $context, $lastError);
// Validate against schema $validation = $this->validateSchema($data, $schema);
if ($validation['valid'] { return $data; }
// Store validation errors for next attempt $lastError = implode(', ', $validation['errors'];
if ($attempt >= $this->maxRetries) { throw new \RuntimeException( "Schema validation failed after {$this->maxRetries} attempts: {$lastError}" ); }
} catch (\Exception $e) { if ($attempt >= $this->maxRetries) { throw $e; } $lastError = $e->getMessage(); } }
throw new \RuntimeException('Extraction failed after maximum retries'); }
private function attemptExtraction( string $input, array $schema, string $context, ?string $previousError ): array { $schemaJson = json_encode($schema, JSON_PRETTY_PRINT);
$prompt = "Extract structured data from the input and return as JSON.\n\n";
if ($context) { $prompt .= "Context: {$context}\n\n"; }
$prompt .= "Required JSON Schema:\n{$schemaJson}\n\n";
if ($previousError) { $prompt .= "Previous attempt had errors: {$previousError}\n"; $prompt .= "Please fix these issues and try again.\n\n"; }
$prompt .= "Input:\n{$input}\n\n"; $prompt .= "Return ONLY valid JSON matching the schema exactly. No explanation or markdown.";
$response = $this->client->messages()->create([ 'model' => 'claude-sonnet-4-5', 'max_tokens' => 4096, 'temperature' => 0.3, 'messages' => [ [ 'role' => 'user', 'content' => $prompt ) ] );
if (empty($response->content) || !isset($response->content[0]->text) { throw new \RuntimeException('Empty response from Claude API'); }
return $this->parseJSON($response->content[0]->text); }
private function parseJSON(string $text): array { // Try to extract JSON from markdown code blocks first if (preg_match('/```json\s*(\{.*\}|\[.*\]\s*```/s', $text, $matches)) { $text = $matches[1]; } elseif (preg_match('/(\{.*\}|\[.*\]/s', $text, $matches)) { // Match the outermost JSON object or array (greedy match) $text = $matches[1]; }
$data = json_decode($text, true);
if (json_last_error() !== JSON_ERROR_NONE) { throw new \RuntimeException('Invalid JSON: ' . json_last_error_msg()); }
if (!is_array($data)) { throw new \RuntimeException('Expected array or object, got: ' . gettype($data)); }
return $data; }
private function validateSchema(array $data, array $schema): array { $validator = new Validator(); $dataObj = json_decode(json_encode($data)); $schemaObj = json_decode(json_encode($schema));
$validator->validate($dataObj, $schemaObj, Constraint::CHECK_MODE_APPLY_DEFAULTS);
$errors = []; if (!$validator->isValid()) { foreach ($validator->getErrors() as $error) { $errors[] = sprintf("[%s] %s", $error['property'], $error['message']; } }
return [ 'valid' => $validator->isValid(), 'errors' => $errors ]; }
/** * Extract array of items */ public function extractList(string $input, array $itemSchema, string $context = ''): array { $schema = [ 'type' => 'object', 'properties' => [ 'items' => [ 'type' => 'array', 'items' => $itemSchema ] ], 'required' => ['items'] ];
$result = $this->extract($input, $schema, $context); return $result['items'] ?? []; }}Expected Result
Section titled “Expected Result”The class provides a robust extraction system that:
- Automatically retries failed extractions up to 3 times
- Validates outputs against the provided schema
- Provides detailed error messages for validation failures
- Handles JSON parsing from various response formats
- Supports both single object and array extraction
Why It Works
Section titled “Why It Works”The extract() method implements a retry loop that attempts extraction up to maxRetries times. Each attempt validates the result against the JSON schema. If validation fails, the errors are fed back into the next prompt, allowing Claude to correct its output. The parseJSON() method uses regex to extract JSON from markdown code blocks (common when Claude formats responses) or directly from the text. The JSON Schema validator ensures the extracted data matches the expected structure and types.
Troubleshooting
Section titled “Troubleshooting”- Error: “Schema validation failed after 3 attempts” — The schema may be too strict or the input text doesn’t contain the required information. Review the validation errors to see which fields are failing.
- JSON parsing errors — If Claude consistently returns malformed JSON, try lowering the temperature (already set to 0.3) or simplifying the schema.
- Infinite retry loop — Ensure the
maxRetrieslimit is properly checked before retrying. The current implementation correctly checks$attempt >= $this->maxRetriesbefore throwing exceptions.
Step 3: Common Data Extraction Schemas (~10 min)
Section titled “Step 3: Common Data Extraction Schemas (~10 min)”Create a Schemas class with pre-built JSON schemas for common data extraction use cases to accelerate development.
Actions
Section titled “Actions”- Define schemas for person, product, event, article, and transaction data types
- Include proper validation with required fields, types, formats, and constraints
- Use nested objects for complex data structures like addresses and locations
<?phpdeclare(strict_types=1);
namespace App\Extraction;
class Schemas{ public static function person(): array { return [ 'type' => 'object', 'properties' => [ 'first_name' => ['type' => 'string'], 'last_name' => ['type' => 'string'], 'email' => [ 'type' => 'string', 'format' => 'email' ], 'phone' => ['type' => 'string'], 'company' => ['type' => 'string'], 'title' => ['type' => 'string'], 'address' => [ 'type' => 'object', 'properties' => [ 'street' => ['type' => 'string'], 'city' => ['type' => 'string'], 'state' => ['type' => 'string'], 'zip' => ['type' => 'string'], 'country' => ['type' => 'string'] ] ] ], 'required' => ['first_name', 'last_name'] ]; }
public static function product(): array { return [ 'type' => 'object', 'properties' => [ 'name' => ['type' => 'string'], 'sku' => ['type' => 'string'], 'description' => ['type' => 'string'], 'price' => [ 'type' => 'number', 'minimum' => 0 ], 'currency' => [ 'type' => 'string', 'default' => 'USD' ], 'category' => ['type' => 'string'], 'brand' => ['type' => 'string'], 'in_stock' => ['type' => 'boolean'], 'specifications' => [ 'type' => 'object', 'additionalProperties' => ['type' => 'string'] ], 'tags' => [ 'type' => 'array', 'items' => ['type' => 'string'] ] ], 'required' => ['name', 'price'] ]; }
public static function event(): array { return [ 'type' => 'object', 'properties' => [ 'title' => ['type' => 'string'], 'description' => ['type' => 'string'], 'start_date' => [ 'type' => 'string', 'format' => 'date-time' ], 'end_date' => [ 'type' => 'string', 'format' => 'date-time' ], 'location' => [ 'type' => 'object', 'properties' => [ 'name' => ['type' => 'string'], 'address' => ['type' => 'string'], 'city' => ['type' => 'string'], 'virtual' => ['type' => 'boolean'] ] ], 'attendees' => [ 'type' => 'array', 'items' => ['type' => 'string'] ], 'organizer' => ['type' => 'string'] ], 'required' => ['title', 'start_date'] ]; }
public static function article(): array { return [ 'type' => 'object', 'properties' => [ 'title' => ['type' => 'string'], 'author' => ['type' => 'string'], 'published_date' => [ 'type' => 'string', 'format' => 'date' ], 'summary' => [ 'type' => 'string', 'maxLength' => 500 ], 'content' => ['type' => 'string'], 'category' => ['type' => 'string'], 'tags' => [ 'type' => 'array', 'items' => ['type' => 'string'] ], 'reading_time_minutes' => [ 'type' => 'integer', 'minimum' => 1 ], 'url' => [ 'type' => 'string', 'format' => 'uri' ] ], 'required' => ['title', 'content'] ]; }
public static function transaction(): array { return [ 'type' => 'object', 'properties' => [ 'transaction_id' => ['type' => 'string'], 'date' => [ 'type' => 'string', 'format' => 'date' ], 'amount' => [ 'type' => 'number', 'minimum' => 0 ], 'currency' => ['type' => 'string'], 'type' => [ 'type' => 'string', 'enum' => ['debit', 'credit', 'transfer'] ], 'description' => ['type' => 'string'], 'merchant' => ['type' => 'string'], 'category' => ['type' => 'string'], 'status' => [ 'type' => 'string', 'enum' => ['pending', 'completed', 'failed', 'cancelled'] ] ], 'required' => ['transaction_id', 'date', 'amount', 'type'] ]; }}Expected Result
Section titled “Expected Result”You’ll have a Schemas class with five ready-to-use schema methods:
person()— Contact information with addressproduct()— Product details with pricing and specificationsevent()— Event information with dates and locationarticle()— Article metadata with content and tagstransaction()— Financial transaction data with status
Why It Works
Section titled “Why It Works”Pre-built schemas follow JSON Schema standards with proper type definitions, format constraints (like email, date-time, uri), and required field specifications. Nested objects allow complex structures like addresses within person records. The schemas include sensible defaults (like currency: 'USD') and validation constraints (like minimum: 0 for prices) to ensure data quality.
Troubleshooting
Section titled “Troubleshooting”- Schema too restrictive — If extraction frequently fails, consider making more fields optional or removing strict format validations temporarily.
- Missing fields — Ensure required fields match what’s actually available in your source text. Claude can’t extract information that isn’t present.
- Type mismatches — If Claude returns strings for numbers, add explicit type coercion or adjust the schema to accept strings and convert later.
Step 4: Advanced Extraction Pipeline (~10 min)
Section titled “Step 4: Advanced Extraction Pipeline (~10 min)”Build a complete example demonstrating the extraction pipeline with multiple real-world use cases using the pre-built schemas.
Actions
Section titled “Actions”- Extract products from a product listing text
- Extract events from an email with meeting information
- Extract transactions from a bank statement text
<?phpdeclare(strict_types=1);
require __DIR__ . '/../vendor/autoload.php';
use App\Extraction\SchemaExtractor;use App\Extraction\Schemas;use ClaudePhp\ClaudePhp;
$client = new ClaudePhp( apiKey: $_ENV['ANTHROPIC_API_KEY']);
$extractor = new SchemaExtractor($client);
// Example 1: Extract products from descriptionecho "=== Extracting Products ===\n";
$productText = <<<TEXTWe have several great items in stock:
1. MacBook Pro 16" with M3 chip - \$2499 Professional laptop with incredible performance In stock, free shipping
2. iPhone 15 Pro (256GB) - \$1099 Latest flagship phone, available in all colors Category: Smartphones
3. AirPods Pro (2nd gen) - \$249 Premium wireless earbuds with ANC Brand: Apple, Currently in stockTEXT;
$products = $extractor->extractList( $productText, Schemas::product(), 'Extract product information from this product listing');
echo json_encode($products, JSON_PRETTY_PRINT) . "\n\n";
// Example 2: Extract events from emailecho "=== Extracting Events ===\n";
$emailText = <<<TEXTHi team,
Quick reminder about our upcoming meetings:
Tech Review MeetingMarch 15, 2025 at 2:00 PM - 3:30 PMConference Room AOrganizer: Sarah Johnson
ClaudePhp PresentationMarch 18, 2025 at 10:00 AM - 11:00 AMVirtual (Zoom link to follow)Organizer: Mike ChenTEXT;
$events = $extractor->extractList( $emailText, Schemas::event(), 'Extract all meeting/event information from this email');
echo json_encode($events, JSON_PRETTY_PRINT) . "\n\n";
// Example 3: Extract transactions from bank statementecho "=== Extracting Transactions ===\n";
$statementText = <<<TEXTRecent Transactions:
03/10/2025 - Amazon.com - \$87.43 - Online Shopping - Completed03/11/2025 - Starbucks - \$5.67 - Food & Dining - Completed03/12/2025 - Salary Deposit - \$3,500.00 - Income - Completed03/13/2025 - Rent Payment - \$1,800.00 - Housing - PendingTEXT;
$transactions = $extractor->extractList( $statementText, Schemas::transaction(), 'Extract transaction information from this bank statement');
echo json_encode($transactions, JSON_PRETTY_PRINT) . "\n\n";Expected Result
Section titled “Expected Result”The script will extract structured data from three different text sources:
- Products with names, prices, descriptions, and stock status
- Events with dates, times, locations, and organizers
- Transactions with amounts, dates, merchants, and status
Why It Works
Section titled “Why It Works”The extractList() method wraps the item schema in a container schema that expects an items array. Claude processes the entire input text and extracts all matching items in a single API call, which is more efficient than processing each item separately. The context parameter helps Claude understand what type of information to look for, improving extraction accuracy.
Troubleshooting
Section titled “Troubleshooting”- Empty results — If
extractList()returns an empty array, check that the input text actually contains the information matching the schema. Claude may not find any matching items. - Partial extraction — If only some items are extracted, the text may be ambiguous. Try providing more context or splitting the extraction into smaller chunks.
- Schema mismatches — If extracted data doesn’t match expected fields, review the schema and adjust field names or types to match what Claude is extracting.
Step 5: Custom Validators (~12 min)
Section titled “Step 5: Custom Validators (~12 min)”Create a CustomValidator class that provides business logic validation beyond what JSON Schema can handle, and integrate it with the extraction pipeline.
Actions
Section titled “Actions”- Implement validation methods for email, phone, URL, date, range, enum, pattern, and length checks
- Create a flexible validation system that accepts rules as arrays
- Provide detailed error messages for each validation failure
- Integrate with SchemaExtractor to add custom validation after schema validation
<?phpdeclare(strict_types=1);
namespace App\Extraction;
class CustomValidator{ private array $errors = [];
public function validate(array $data, array $rules): bool { $this->errors = [];
foreach ($rules as $field => $fieldRules) { $value = $data[$field] ?? null;
foreach ($fieldRules as $rule => $params) { $method = 'validate' . ucfirst($rule); if (method_exists($this, $method)) { $this->$method($field, $value, $params); } } }
return empty($this->errors); }
public function getErrors(): array { return $this->errors; }
private function validateEmail(string $field, $value, $params): void { if ($value && !filter_var($value, FILTER_VALIDATE_EMAIL)) { $this->errors[$field][] = "Invalid email format"; } }
private function validatePhone(string $field, $value, $params): void { if ($value && !preg_match('/^\+?[\d\s\-\(\)]+$/', $value)) { $this->errors[$field][] = "Invalid phone format"; } }
private function validateUrl(string $field, $value, $params): void { if ($value && !filter_var($value, FILTER_VALIDATE_URL)) { $this->errors[$field][] = "Invalid URL format"; } }
private function validateDate(string $field, $value, $params): void { if ($value) { $date = \DateTime::createFromFormat($params['format'] ?? 'Y-m-d', $value); if (!$date || $date->format($params['format'] ?? 'Y-m-d') !== $value) { $this->errors[$field][] = "Invalid date format"; } } }
private function validateRange(string $field, $value, $params): void { if ($value !== null) { if (isset($params['min'] && $value < $params['min'] { $this->errors[$field][] = "Value below minimum {$params['min']}"; } if (isset($params['max'] && $value > $params['max'] { $this->errors[$field][] = "Value above maximum {$params['max']}"; } } }
private function validateEnum(string $field, $value, $params): void { if ($value && !in_array($value, $params['values']) { $this->errors[$field][] = "Value not in allowed list: " . implode(', ', $params['values']; } }
private function validatePattern(string $field, $value, $params): void { if ($value && !preg_match($params['regex'], $value)) { $this->errors[$field][] = $params['message'] ?? "Value doesn't match required pattern"; } }
private function validateLength(string $field, $value, $params): void { if ($value) { $length = strlen($value); if (isset($params['min'] && $length < $params['min'] { $this->errors[$field][] = "Length below minimum {$params['min']}"; } if (isset($params['max'] && $length > $params['max'] { $this->errors[$field][] = "Length above maximum {$params['max']}"; } } }
private function validateRequired(string $field, $value, $params): void { if ($params && ($value === null || $value === '')) { $this->errors[$field][] = "Field is required"; } }}Integration Example
Section titled “Integration Example”Here’s how to use CustomValidator with SchemaExtractor:
<?phpdeclare(strict_types=1);
require __DIR__ . '/../vendor/autoload.php';
use App\Extraction\SchemaExtractor;use App\Extraction\CustomValidator;use App\Extraction\Schemas;use ClaudePhp\ClaudePhp;
$client = new ClaudePhp( apiKey: $_ENV['ANTHROPIC_API_KEY']);
$extractor = new SchemaExtractor($client);$validator = new CustomValidator();
// Extract person data$personText = "John Doe\njohn.doe@example.com\n+1-555-123-4567";$person = $extractor->extract($personText, Schemas::person());
// Apply custom validation rules$rules = [ 'email' => ['email' => true], 'phone' => ['phone' => true], 'first_name' => ['required' => true, 'length' => ['min' => 2, 'max' => 50]]];
if (!$validator->validate($person, $rules)) { echo "Validation errors:\n"; print_r($validator->getErrors());} else { echo "Data is valid!\n"; echo json_encode($person, JSON_PRETTY_PRINT) . "\n";}Expected Result
Section titled “Expected Result”You’ll have a CustomValidator class that can validate:
- Email addresses using PHP’s
FILTER_VALIDATE_EMAIL - Phone numbers with regex pattern matching
- URLs using PHP’s
FILTER_VALIDATE_URL - Dates in custom formats using
DateTime::createFromFormat - Numeric ranges with min/max constraints
- Enum values against allowed lists
- Regex patterns for custom validation rules
- String length constraints
Why It Works
Section titled “Why It Works”The validator uses a rule-based system where each field can have multiple validation rules. The validate() method iterates through rules and calls corresponding validation methods dynamically using method_exists(). Each validation method checks the value and adds errors to the $errors array if validation fails. This allows combining JSON Schema validation (structural) with custom validation (business logic) for comprehensive data quality checks.
When to use CustomValidator vs JSON Schema:
- JSON Schema: Use for structural validation (types, formats, required fields, nested structures)
- CustomValidator: Use for business logic validation (complex rules, cross-field validation, domain-specific constraints)
- Best Practice: Use JSON Schema first for structure, then CustomValidator for business rules
Troubleshooting
Section titled “Troubleshooting”- Validation not running — Ensure the rule name matches the method name (e.g.,
'email'rule callsvalidateEmail()method). Theucfirst()function capitalizes the rule name to match the method naming convention. - False positives — Some validators (like phone) use regex that may be too strict. Adjust the regex pattern to match your data format requirements.
- Date validation failures — Ensure the date format in
$params['format']matches the actual date format in your data. PHP’sDateTime::createFromFormatis strict about format matching.
Step 6: Batch Extraction (~8 min)
Section titled “Step 6: Batch Extraction (~8 min)”Create a BatchExtractor class that processes multiple inputs efficiently, handling successes and errors gracefully.
Actions
Section titled “Actions”- Implement batch processing that extracts data from multiple inputs
- Track successes and errors separately for each item
- Provide summary statistics about the batch operation
<?phpdeclare(strict_types=1);
require __DIR__ . '/../vendor/autoload.php';
use App\Extraction\SchemaExtractor;use App\Extraction\Schemas;
class BatchExtractor{ public function __construct( private SchemaExtractor $extractor ) {}
public function extractBatch(array $inputs, array $schema, string $context = ''): array { $results = []; $errors = [];
foreach ($inputs as $index => $input) { try { $results[$index] = $this->extractor->extract($input, $schema, $context); } catch (\Exception $e) { $errors[$index] = [ 'error' => $e->getMessage(), 'input' => $input ]; } }
return [ 'results' => $results, 'errors' => $errors, 'success_count' => count($results), 'error_count' => count($errors), 'total' => count($inputs) ]; }
public function extractFromMultipleTexts(string $combinedText, array $itemSchema): array { // Let Claude extract all items in one go return $this->extractor->extractList($combinedText, $itemSchema); }}
$client = new ClaudePhp( apiKey: $_ENV['ANTHROPIC_API_KEY']);
$extractor = new SchemaExtractor($client);$batchExtractor = new BatchExtractor($extractor);
// Example: Extract contacts from multiple business cards$businessCards = [ "John Smith\nCEO, TechCorp\njohn@techcorp.com\n555-1234", "Jane Doe\nCTO, StartupXYZ\njane.doe@startupxyz.com\n555-5678", "Bob Johnson\nVP Engineering, MegaSoft\nbob.j@megasoft.com\n555-9999"];
$result = $batchExtractor->extractBatch( $businessCards, Schemas::person(), 'Extract contact information from business card');
echo "Batch Extraction Results:\n";echo "Success: {$result['success_count']}/{$result['total']}\n";echo "Errors: {$result['error_count']}\n\n";
echo "Extracted Data:\n";echo json_encode($result['results'], JSON_PRETTY_PRINT) . "\n";Expected Result
Section titled “Expected Result”The batch extractor will process all business cards and return:
- A
resultsarray with successfully extracted contact information - An
errorsarray with any failures (indexed by input position) - Summary statistics:
success_count,error_count, andtotal
Why It Works
Section titled “Why It Works”The extractBatch() method processes each input independently, catching exceptions for individual items so one failure doesn’t stop the entire batch. This allows partial success scenarios where some items extract successfully while others fail. The method returns both results and errors, giving you complete visibility into the batch operation. The extractFromMultipleTexts() method processes all items in a single API call, which is more efficient when you have many items in one text source.
Troubleshooting
Section titled “Troubleshooting”- All items failing — If every item in a batch fails, check that the schema matches the input format. A single schema mismatch will cause all items to fail.
- Memory issues — Processing very large batches may consume significant memory. Consider processing in chunks or using streaming (Step 7) for large datasets.
- Rate limiting — Batch processing makes multiple API calls quickly. Implement rate limiting or delays between batches if you hit API rate limits.
Step 7: Streaming Structured Output (~8 min)
Section titled “Step 7: Streaming Structured Output (~8 min)”Create a StreamingExtractor class that processes structured output as it streams from Claude, useful for large responses.
Actions
Section titled “Actions”- Use dependency injection to pass the client to the constructor
- Use the streaming API to receive data incrementally
- Buffer the streamed content until complete
- Parse JSON from the complete buffer with proper error handling
<?phpdeclare(strict_types=1);
require __DIR__ . '/../vendor/autoload.php';
use App\Extraction\Schemas;use ClaudePhp\ClaudePhp;
$client = new ClaudePhp( apiKey: $_ENV['ANTHROPIC_API_KEY']);
// Example usage$inputText = "John Doe\njohn.doe@example.com\n+1-555-123-4567";$extractor = new StreamingExtractor($client);$schema = Schemas::person();$result = $extractor->extractWithStreaming($inputText, $schema);echo json_encode($result, JSON_PRETTY_PRINT) . "\n";
class StreamingExtractor{ private string $buffer = '';
public function __construct( private \ClaudePhp\ClaudePhp $client ) {}
public function extractWithStreaming(string $input, array $schema): array { $schemaJson = json_encode($schema, JSON_PRETTY_PRINT);
$prompt = <<<PROMPTExtract data from this input as JSON matching this schema:
{$schemaJson}
Input:{$input}
Return only valid JSON.PROMPT;
$stream = $this->client->messages()->createStreamed([ 'model' => 'claude-sonnet-4-5', 'max_tokens' => 4096, 'messages' => [ ['role' => 'user', 'content' => $prompt] ] ];
$this->buffer = '';
foreach ($stream as $event) { if ($event->type === 'content_block_delta') { if (isset($event->delta->text)) { $this->buffer .= $event->delta->text; echo "."; // Progress indicator } } }
echo "\n";
return $this->parseJSON($this->buffer); }
private function parseJSON(string $text): array { // Try to extract JSON from markdown code blocks if (preg_match('/```json\s*(\{.*\})\s*```/s', $text, $matches)) { $text = $matches[1]; } elseif (preg_match('/(\{.*\})/s', $text, $matches)) { $text = $matches[1]; }
$data = json_decode($text, true);
if (json_last_error() !== JSON_ERROR_NONE) { throw new \RuntimeException('Invalid JSON in stream: ' . json_last_error_msg()); }
if (!is_array($data)) { throw new \RuntimeException('Expected array or object, got: ' . gettype($data)); }
return $data; }}Expected Result
Section titled “Expected Result”The streaming extractor will process the response as it arrives, showing progress dots (.) for each chunk received, then parse and return the complete JSON structure.
Why It Works
Section titled “Why It Works”The createStreamed() method returns an iterable stream of events. We iterate through events looking for content_block_delta events that contain text chunks. Each chunk is appended to a buffer. Once streaming completes, we parse the complete buffer as JSON. Streaming is useful for large responses because you can start processing data as it arrives rather than waiting for the complete response, and it provides visual feedback to users.
Troubleshooting
Section titled “Troubleshooting”- Incomplete JSON — If streaming stops before JSON is complete, the buffer may contain partial JSON that fails to parse. Ensure the stream completes fully before parsing. Check that
max_tokensis sufficient for your response size. - No progress indicators — The dots (
.) should appear as data streams. If they don’t, check that the stream is actually streaming and not buffered. Verify the event type iscontent_block_delta. - Memory usage — For very large streams, consider processing JSON incrementally if possible, though this is complex with nested structures.
- Constructor error — The
StreamingExtractornow requires the client in the constructor. Make sure to instantiate it withnew StreamingExtractor($client). - Error: “Expected array or object” — The parsed JSON must be an object or array. If Claude returns a primitive value, adjust your schema or prompt to request an object wrapper.
When to Use Structured Outputs vs Tool Use
Section titled “When to Use Structured Outputs vs Tool Use”Understanding when to use structured outputs versus tool use (from Chapter 11) is important:
Use Structured Outputs When:
- Extracting data from text (documents, emails, user input)
- Parsing unstructured information into structured formats
- Converting text to JSON/arrays for storage or processing
- One-way data extraction (no action needed)
Use Tool Use When:
- Claude needs to perform actions (database queries, API calls, file operations)
- Multi-step workflows requiring external system interaction
- Dynamic decision-making based on tool results
- Two-way communication (Claude requests → you execute → Claude responds)
Example Comparison:
// Structured Output: Extract data from text$contact = $extractor->extract($businessCard, Schemas::person());// Result: Array with contact information
// Tool Use: Query database based on extracted data$tools = [ [ 'name' => 'search_customer', 'description' => 'Search for customer in database', 'input_schema' => [ 'type' => 'object', 'properties' => [ 'email' => ['type' => 'string'] ] ] ]];// Claude can call this tool to look up the customerBest Practice: Use structured outputs to extract data, then use tool use to act on that data.
Best Practices
Section titled “Best Practices”1. Dependency Injection
Section titled “1. Dependency Injection”Always pass dependencies (like the Anthropic client) through constructors or method parameters rather than using global variables:
// ✓ Good: Dependency injectionclass SchemaExtractor{ public function __construct(private \ClaudePhp\ClaudePhp $client) {}}
// ❌ Bad: Global variablefunction extract() { global $client; // Avoid this}2. Schema Design
Section titled “2. Schema Design”// ✓ Good: Clear, specific schema$schema = [ 'type' => 'object', 'properties' => [ 'price' => [ 'type' => 'number', 'minimum' => 0, 'description' => 'Price in USD' ], 'date' => [ 'type' => 'string', 'pattern' => '^\d{4}-\d{2}-\d{2}$', 'description' => 'Date in YYYY-MM-DD format' ] ], 'required' => ['price', 'date']];
// ❌ Bad: Vague, loose schema$schema = [ 'type' => 'object', 'properties' => [ 'data' => ['type' => 'string'] ]];3. Error Recovery
Section titled “3. Error Recovery”// Always implement retry logictry { $data = $extractor->extract($input, $schema);} catch (\Exception $e) { // Log error error_log("Extraction failed: " . $e->getMessage());
// Fallback strategy $data = $this->manualExtraction($input);}4. Validation Layers
Section titled “4. Validation Layers”// Layer 1: JSON Schema validation (structural)$validation = $extractor->validateSchema($data, $schema);if (!$validation['valid'] { // Handle schema validation errors}
// Layer 2: Custom business logic validation$customValidator = new CustomValidator();$rules = [ 'email' => ['email' => true], 'price' => ['range' => ['min' => 0, 'max' => 10000]]];if (!$customValidator->validate($data, $rules)) { // Handle custom validation errors $errors = $customValidator->getErrors();}
// Layer 3: Data sanitization$sanitized = $this->sanitizeData($data);5. JSON Parsing Robustness
Section titled “5. JSON Parsing Robustness”Always handle edge cases when parsing JSON from Claude responses:
// ✓ Good: Multiple extraction strategies with error handlingprivate function parseJSON(string $text): array{ // Try markdown code blocks first if (preg_match('/```json\s*(\{.*\})\s*```/s', $text, $matches)) { $text = $matches[1]; } elseif (preg_match('/(\{.*\})/s', $text, $matches)) { $text = $matches[1]; }
$data = json_decode($text, true);
if (json_last_error() !== JSON_ERROR_NONE) { throw new \RuntimeException('Invalid JSON: ' . json_last_error_msg()); }
if (!is_array($data)) { throw new \RuntimeException('Expected array or object'); }
return $data;}
// ❌ Bad: No error handlingprivate function parseJSON(string $text): array{ return json_decode($text, true) ?? []; // Silent failure}6. Integration with Error Handling
Section titled “6. Integration with Error Handling”For production systems, integrate with error handling patterns from Chapter 10:
use App\Claude\ResilientClaudeClient;use App\Claude\ExponentialBackoff;
class ProductionExtractor extends SchemaExtractor{ public function __construct( private ResilientClaudeClient $resilientClient, private ExponentialBackoff $backoff ) { parent::__construct($resilientClient->getClient()); }
public function extract(string $input, array $schema, string $context = ''): array { return $this->backoff->execute(function () use ($input, $schema, $context) { return parent::extract($input, $schema, $context); }); }}7. Caching Strategies
Section titled “7. Caching Strategies”Cache extraction results for repeated inputs to reduce API costs:
class CachedExtractor extends SchemaExtractor{ public function __construct( Anthropic $client, private \Psr\SimpleCache\CacheInterface $cache, private int $ttl = 3600 ) { parent::__construct($client); }
public function extract(string $input, array $schema, string $context = ''): array { $cacheKey = 'extract:' . md5($input . serialize($schema) . $context);
if ($this->cache->has($cacheKey)) { return $this->cache->get($cacheKey); }
$result = parent::extract($input, $schema, $context); $this->cache->set($cacheKey, $result, $this->ttl);
return $result; }}8. Schema Versioning
Section titled “8. Schema Versioning”Version your schemas to handle changes over time:
class VersionedSchema{ public static function person(int $version = 2): array { return match($version) { 1 => self::personV1(), 2 => self::personV2(), default => throw new \InvalidArgumentException("Unknown schema version: {$version}") }; }
private static function personV1(): array { return [ 'type' => 'object', 'properties' => [ 'name' => ['type' => 'string'], 'email' => ['type' => 'string'] ] ]; }
private static function personV2(): array { return [ 'type' => 'object', 'properties' => [ 'first_name' => ['type' => 'string'], 'last_name' => ['type' => 'string'], 'email' => ['type' => 'string', 'format' => 'email'] ], 'required' => ['first_name', 'last_name'] ]; }}Exercises
Section titled “Exercises”Exercise 1: Extract Invoice Data
Section titled “Exercise 1: Extract Invoice Data”Goal: Create a schema and extraction function for invoice data.
Create a new schema method invoice() in the Schemas class that includes:
- Invoice number (required string)
- Date (required date)
- Due date (date)
- Customer information (object with name, email, address)
- Line items (array of objects with description, quantity, unit_price, total)
- Subtotal, tax, and total amounts (numbers)
- Status (enum: ‘draft’, ‘sent’, ‘paid’, ‘overdue’)
Then create an extraction example that processes invoice text and extracts this structured data.
Validation: Test with sample invoice text and verify all required fields are extracted correctly.
Exercise 2: Add Custom Validation Rules
Section titled “Exercise 2: Add Custom Validation Rules”Goal: Extend the CustomValidator class with new validation rules.
Add validation methods for:
validateCreditCard()— Validates credit card numbers using Luhn algorithmvalidatePostalCode()— Validates US ZIP codes (5 digits or 5+4 format)validateAge()— Validates age is between 0 and 150
Create a test that validates person data using these new rules.
Validation: Ensure invalid data is caught and valid data passes all checks.
Further Reading
Section titled “Further Reading”- Official PHP SDK Documentation — The official Anthropic PHP SDK on GitHub
- Claude-PHP-SDK — Community resources and examples for Claude with PHP
- Anthropic API Documentation — Complete API reference and guides
- PHP SDK Composer Package — Official package on Packagist
Wrap-up
Section titled “Wrap-up”Congratulations! You’ve completed Chapter 15: Structured Outputs with JSON. Here’s what you’ve accomplished:
- ✓ Built a complete structured data extraction system with retry logic
- ✓ Created reusable schema definitions for common data types
- ✓ Implemented multi-layer validation (JSON Schema + custom validators)
- ✓ Built batch processing capabilities for efficient multi-item extraction
- ✓ Added streaming support for large responses
- ✓ Learned error recovery techniques and fallback strategies
- ✓ Understood how to design production-ready extraction pipelines
You now have the knowledge and tools to extract reliable, structured data from Claude responses in your PHP applications. These techniques are essential for building production applications that depend on AI-generated structured data.
Further Reading
Section titled “Further Reading”- JSON Schema Specification — Official JSON Schema documentation and validation rules
- Anthropic API Documentation — Official Claude API reference with
response_formatparameter details - Chapter 10: Error Handling — Integrate retry logic and error recovery
- Chapter 11: Tool Use — Learn when to use tools vs structured outputs
- PHP JSON Functions — PHP’s built-in JSON encoding and decoding functions
- justinrainbow/json-schema — PHP JSON Schema validator library documentation
Key Takeaways
Section titled “Key Takeaways”- ✓ Use native
response_formatfor Sonnet 4.5+ models to guarantee schema compliance - ✓ Fallback to prompt-based extraction for older models or when native format isn’t supported
- ✓ Use explicit JSON schemas to define expected output structure
- ✓ Implement retry logic with error feedback for robust extraction
- ✓ Validate outputs using both JSON Schema and custom validators
- ✓ Extract JSON from markdown code blocks automatically when using prompt-based method
- ✓ Lower temperature (0.3-0.5) produces more consistent structured outputs
- ✓ Pre-built schemas accelerate common extraction tasks
- ✓ Batch processing improves efficiency for multiple items
- ✓ Always handle JSON parsing errors gracefully
- ✓ Include descriptions in schemas to improve extraction accuracy
- ✓ Use structured outputs for data extraction, tool use for actions
- ✓ Cache extraction results to reduce API costs for repeated inputs
- ✓ Version schemas to handle changes over time
- ✓ Test extraction with edge cases and malformed inputs
💻 Code Samples
Section titled “💻 Code Samples”All code examples from this chapter are available in the GitHub repository:
Clone and run locally:
git clone https://github.com/dalehurley/codewithphp.gitcd codewithphp/code/claude-php/chapter-15composer installexport ANTHROPIC_API_KEY="sk-ant-your-key-here"php examples/01-basic-structured-output.php